
你让 agent 做一个大型 refactor。前 15 分钟表现优秀——精准定位问题,给出合理方案,代码写得干净。你很满意,去泡了杯咖啡。
半小时回来,发现它已经声明自己做完了。你一看,一堆边界情况没处理。或者更常见的——它开始做计划外的事情了,你让它改 auth module,它在重构 logging system,“因为我发现这里也有问题”。你停下来问它:“你还记得自己在做啥吗?“它答不上来。
上一篇 Harness Engineering 的核心论点是:别期望 AI 行为正确,构造一个结构让它想不正确都难。
那篇文章的假设是 task 在分钟级别完成。Agent 进来,跑 pipeline,输出结果,验证,结束。结构是静态的,够用。
但 orchestrator 的架构升级速度比我们预想的快得多。Claude Code 的 --max-turns 可以让 agent 连续跑几百轮;Devin、Codex 这类产品把 multi-hour autonomous session 变成了常态;自建 agent 做 codebase migration、长报告生成,一跑就是几个小时。Agent 正在从”完成一个确定性任务”演化为”处理 long-running 的、边界模糊的任务”。用户期待完成的任务越来越 vague,边界越来越宽,越来越难闭环 verify。
当 task 从分钟级变成小时级,那个静态结构就不够了。
Prompt Engineering 的物理极限
Prompt engineering 本质上是在做一件事:在 context window 的起始位置注入信号,期望这个信号在整个 generation 过程中持续生效。
短对话里这能 work。但 long-run task 把前提全部摧毁。
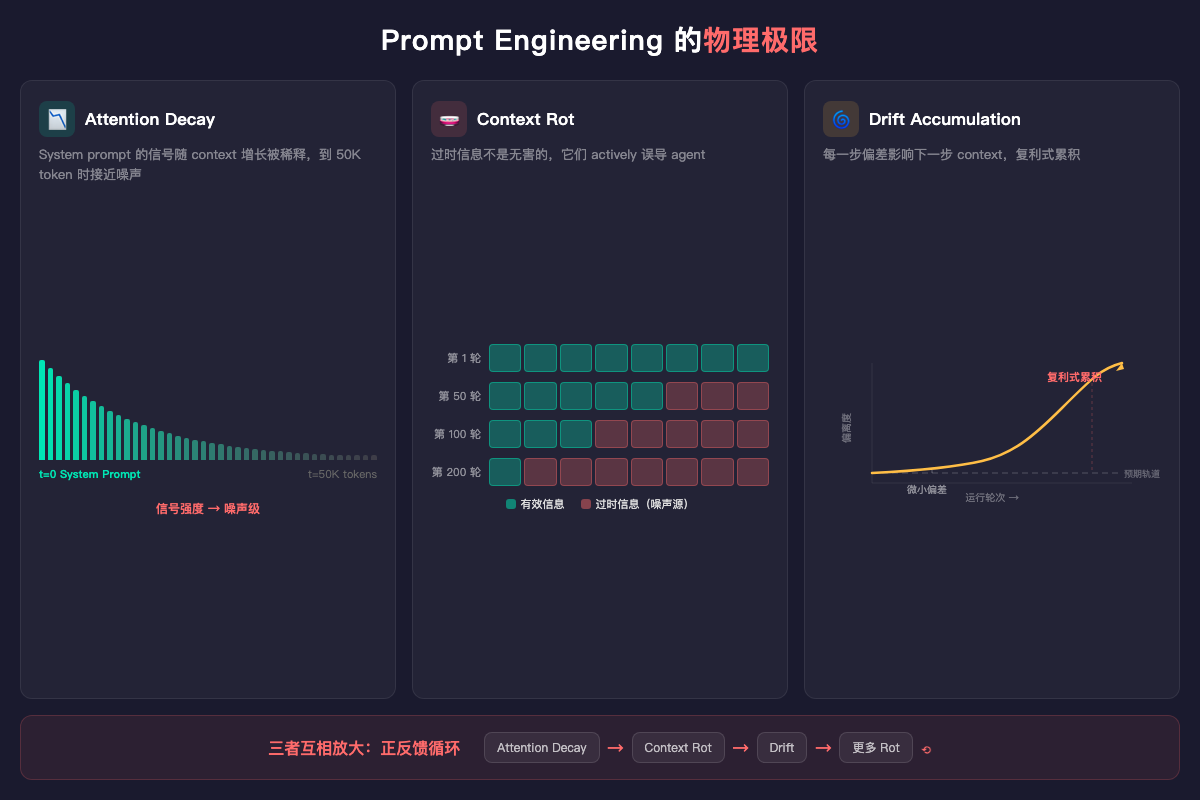
Attention Decay。 Transformer 的 attention 不是均匀的。随着 context 变长,early tokens 的 attention weight 被稀释。你在 system prompt 里写的 “be thorough”,到第 50K token 的时候,对 generation 的影响接近噪声。
Context Rot。 不只是 attention 衰减。Long-run task 中,context 会积累大量过时信息——之前的决策、已经被推翻的假设、中间状态的输出。这些”腐烂”的 context 不是无害的,它们 actively 误导 agent。比 attention decay 更危险:attention decay 是信号变弱,context rot 是噪声变强。
Drift Accumulation。 每一轮 generation 都有微小的偏差。短对话里,5 轮偏差累积不到哪去。Long-run task 跑几百轮,偏差不是线性累积的——每一步的偏差影响下一步的 context,是 复利式 的。
这三个问题不是独立的,它们互相放大。Attention decay 让 agent 更容易被 rotted context 误导,误导导致更大的 drift,drift 产生更多 rotted context。正反馈循环。
所以 prompt engineering 在 long-run 场景下的失效不是渐进的,是 断崖式 的。存在一个临界点,过了之后 system prompt 基本失效。
Prompt Engineering 是 Harness Engineering 的子集
之前的认知是:prompt engineering、context engineering、harness engineering 是三个并列的范式。
我现在认为更准确的关系是:

Prompt Engineering — 控制 agent 的起点
Context Engineering — 控制 agent 的输入
Harness Engineering — 控制 agent 的轨道Context engineering 是始终需要的底座——不管用什么范式,agent 的能力上限取决于你给它的 context 质量。
Prompt engineering 和 harness engineering 的关系,不是替代,是包含。Prompt engineering 是 harness engineering 在 prompt 层面的投射。
核心区别在于 信号传递方式。不是二分法,是三层:
In-band static。 System prompt——在 context window 起始位置注入一次,然后祈祷它持续生效。不管你在里面写了 persona、anti-rationalization table 还是别的什么,它们都是同一个东西:t=0 写入的 static text。Context 越长,信号越弱。这就是 prompt engineering 的全部手段。
In-band dynamic。 周期性重注入——每隔 N 轮把目标和约束重新写入 context window。具体实现因 orchestrator 而异:loop prompt、cron 触发、hook 驱动注入都可以。它仍然活在 context window 里,仍然和 content 竞争 attention,但它利用了 recency bias:最近注入的 token 比 50K token 之前的 system prompt 有更高的 attention weight。不是免疫衰减,是 用高频重复对抗衰减。比 static 强,但 context 继续膨胀时,重注入的频率也要提高,成本不是零。
Out-of-band。 Hook 不活在 context window 里,它在 agent 的 action 边界上执行——pre-commit hook 不管你跑了多少轮都会触发。Gen-eval separation 不依赖 agent 自己记得要自检——evaluator 是独立进程,带着新鲜的 context window 进场。这些手段不和 content 竞争 attention,不受 context 长度影响。
但 harness 不只是 out-of-band code。这是上一篇没说清楚的:
Harness 是一个 mindset——“我应该如何控制 LLM”——在 prompt、架构、代码三个层面的投射。
Anti-rationalization table 是 in-band static,但思维模式是 harness 的——不是在说服 LLM,是在概率空间堵死偷懒路径。Loop prompt 是 in-band dynamic,设计意图也是 harness 的——我不信任 LLM 会记住目标,所以构造一个结构周期性提醒它。Hook 是 out-of-band code,也是 harness 的——在 action 边界上做 enforcement,不管 context 多长都生效。
短 task 里,prompt 层面的 harness 够用。Long-run task 里,你需要三个层面同时工作。
L0-L3 在 Long-Run 场景下的进化
上一篇建立的 L0-L3 四层框架,每一层在 long-run 场景下都需要进化。

L0: Zero Trust — 加入时间维度
上一篇的 L0:永远假设 LLM 会偷懒、会编造、会跳步骤。
Long-run 场景下,L0 需要加一条:不信任 LLM 的行为在时间维度上是稳定的。
一个 agent 在第 1 小时表现优秀,不代表第 5 小时还行。不是因为模型变了——是因为 context 变了。Attention decay + context rot + drift accumulation,同一个模型在不同时刻的 effective capability 不同。
新的 decision rule:不仅验证每个输出,还要验证行为随时间的一致性。 第 100 轮的输出质量和第 1 轮的输出质量,应该是可比较的。
L1: Shape — 从一次性塑造到持续塑造
上一篇的 L1 有六个机制:persona、anti-pattern、anti-rationalization、output structure、scope anchoring、quality gate。它们都是在 task 开始时一次性注入的。
Long-run 场景下,三个进化:
Periodic Re-injection。 不是说一次就完。关键约束需要周期性重新注入——不是 repeat prompt(那是 in-band,效果会递减),而是 harness 层面的 context refresh。清除过时信息,重新锚定目标和边界。这就是 loop prompt 的设计意图。
Dynamic Scope Anchoring。 短 task 的 scope 是静态的——“只看这几个文件”。Long-run task 的 scope 会自然扩展。Agent 发现 bug 在数据库层,需要扩展 scope 到 schema。每次 scope expansion 需要显式 checkpoint:当前边界是什么,为什么要扩,扩展后的 blast radius 是什么,需不需要人类确认。低风险自动批,高风险要确认——graduated escalation。
Temporal Anti-Rationalization。 短 task 的偷懒是跳步骤、hedge、“code looks correct”。Long-run task 有新的偷懒模式——无限循环在安全区。Agent 持续做简单的子 task,回避困难的决策。“我还在调研”、“需要进一步分析”、“让我先看看另一个相关问题”——这是 long-run 版的 “code looks correct”。表面上很忙,实际上没有实质进展。
这种偷懒比短 task 的更难检测,因为每一步都”合理”。只有从时间维度看——连续 N 轮没有新 artifact 产出——才能发现。
但只堵偷懒路径不够。Agent 说”我看不到 console log 所以无法验证”——你用 anti-rationalization table 堵住这条借口,但如果它真的没有访问 log 的能力,堵了也白堵。完整的策略是三层递进:
- 堵偷懒路径。 Anti-rationalization 制止”我做不到”式的借口。
- 提供 tool 和 skill。 给 agent 访问 console log 的 tool,构建 skill 指导它如何拿到反馈信号。堵了借口,同时给它真正的能力。
- 引导 E2E 闭环。 更高级的做法:让 agent 先写 E2E test case,自己实现,自己跑测试,自己 fix test 和 code 两端。甚至启动不同 persona 做全生命周期验证——实现者写代码,reviewer 审代码,tester 跑测试,每个角色独立评判。
第一层是”不让它逃”,第二层是”给它武器”,第三层是”让它自己能闭环”。Long-run task 里,agent 的自我校正能力比外部监控更可持续——你不可能每一轮都人工检查,但你可以构造一个结构让 agent 自己持续验证自己。
L2: Flow — 从 DAG 到 Event Loop
上一篇的 L2 假设 flow 是 DAG——有明确的起点、终点、拓扑顺序。Review 并行 dispatch,Build 串行 evaluate,每个 gate 是确定性的。
Long-run task 的 flow 不是 DAG,是 event loop + state machine。没有预定义的终点,agent 持续运行,响应事件,状态在多个可能的值之间转换。
具体场景:agent 在做 codebase migration,按计划逐模块迁移。跑到第 3 个模块时发现 API incompatibility,需要先回去改第 1 个模块的接口。改完接口,发现依赖这个接口的测试也要更新。更新测试时又触发了 CI failure,需要排查。——这不是线性的 DAG,每一步都可能因为新发现的事件跳转到不同状态。Flow 的设计不再是画一张固定的图,而是定义状态集合、事件类型、和转换规则。
三个维度的进化: 从预定义的 DAG 变成动态的 event-driven 流程。Agent 不是沿着固定路径走,而是根据事件决定下一步。这意味着 flow 的设计不再是画一张图,而是定义事件类型、状态转换规则、和边界条件。
Gen-Eval Separation。 上一篇说做事的人不评价。Long-run 场景下这个原则更重要——不是做完才 eval,是 continuous eval。就像生产系统不是部署完才监控,是持续监控。Eval 的频率和粒度需要重新设计。
Context Isolation。 上一篇说 evaluator 不读 implementer 的推理。Long-run 场景下,context isolation 的挑战更大——context 在持续膨胀。不只是 isolate,还需要 主动 eviction——定期清理不再相关的 context,保持 signal-to-noise ratio。
L3: Enforcement — 从 Post-Hoc 到 Runtime
上一篇的 L3 是事后检查——agent 输出了,L3 验证。Verify、synthesize、diff。
Long-run task 不能只靠事后。需要 运行时 guardrail——三个 in-flight 检查:
Scope Check。 每个 action,检查是否还在 task boundary 内。不是 LLM 判断,是 diff against declared boundary。
Progress Check。 距离上次有实质进展过了多久。检测”无限调研”式偷懒。Heuristic:连续 N 轮没有新 artifact 产生 → 触发 escalation。
Consistency Check。 当前 action 和之前的决策是否一致。检测 context rot 导致的矛盾——agent 在第 50 轮决定用方案 A,第 150 轮忘了这个决策,开始做方案 B。
这三个检查都可以是 deterministic 的,不需要 LLM 判断。这就是 L3 的核心优势——不受 attention decay 影响。
从”设计结构”到”运营系统”
上面说的所有进化,指向一个根本性的范式迁移:
Task-scoped harness = 设计。 在 task 开始前设计好结构——persona、anti-patterns、flow topology、verification rules——然后 LLM 在里面跑。设计是静态的,运行是有限的。
Long-run harness = 运营。 结构不是设计一次就完了。它需要监控、诊断、干预、迭代。
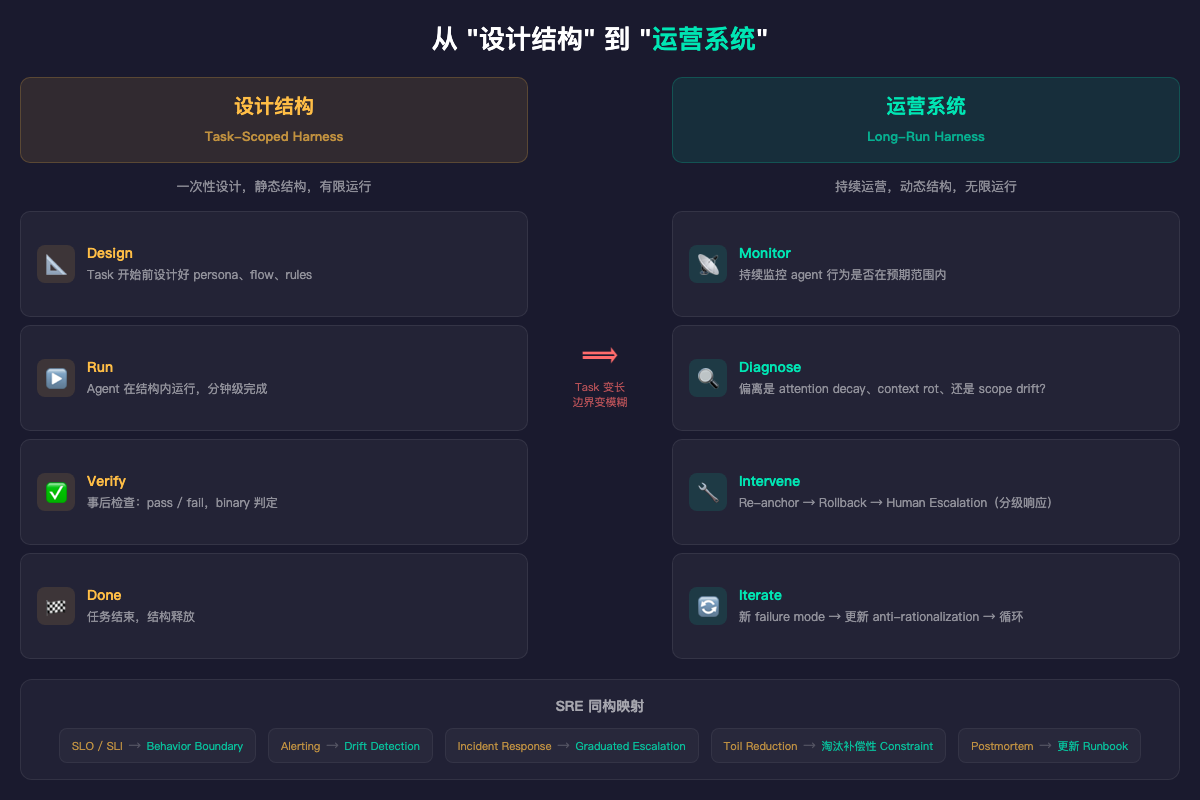
这和 SRE(Site Reliability Engineering)不是 metaphor,是同构:
| SRE | Long-run Harness |
|---|---|
| Service 24/7 运行 | Agent 持续运行 |
| SLO/SLI 定义可接受范围 | Agent 的 behavior boundary |
| Monitoring + Alerting | Drift detection + escalation |
| Incident response | Re-anchor → rollback → human escalation |
| Toil reduction | 补偿性 constraint 随模型升级淘汰 |
| Postmortem → 更新 runbook | 新 failure mode → 更新 anti-rationalization |
Verification 的重新定义。 短 task 的 verification 是 binary 的——pass 或 fail。Long-run task 需要借鉴 SRE 的 error budget 思路:不是问”对不对”,而是问”偏离可接受轨道多远了”。在 budget 内运行不干预,超出了才触发 re-anchor 或 human escalation。
Graceful Degradation。 短 task 出问题,re-dispatch,反正就几分钟。Long-run task 重来一次可能是几小时。需要分级响应:
- 检测到轻微 drift → re-anchor(成本最低)
- Re-anchor 无效 → 回退到最近的 checkpoint(中等成本)
- Checkpoint 也不行 → 升级给人类,带完整 audit trail(最高成本)
“为什么不直接拆成短 task?” 这是最自然的反论。答案是:拆 task 本身就是 harness。把一个 3 小时的 session 拆成 20 个 10 分钟的 sub-task,每个 sub-task 有明确的 input/output/done criteria,完成后 checkpoint,开始下一个——这不是在回避 long-run 问题,这恰恰是 harness 思维的应用。你在 orchestration 层做了 scope control 和 drift prevention。
但有些 task 天然不可拆。跨几十个文件的大型 refactor,需要 agent 持续持有 cross-file 的 mental model;复杂 bug 的诊断,context 链条中断就要从头来。对这类 task,sub-task decomposition 是第一道防线,但不够——你还需要 runtime 的 drift detection 和 graceful degradation。
什么会消失,什么会留下
上一篇区分了 补偿性 constraint(编码模型弱点,会随模型进步淘汰)和 结构性 constraint(编码工程最佳实践,永远不淘汰)。
在 long-run 场景下,这个比例会反转。
短 task 的 harness(比如当前的 OPC)大约 60-70% 补偿性,30-40% 结构性。模型变强,大部分 constraint 会被淘汰。
Long-run harness 可能是 80% 结构性,20% 补偿性。因为:
- Periodic re-anchoring 是结构性的。 再强的模型也有 attention decay——这是 transformer architecture 的固有属性,不是能力问题。
- Continuous drift detection 是结构性的。 再强的模型在几百轮后也会 drift——复利式偏差不会因为模型变强而消失。
- Gen-eval separation 在 long-run 下更结构性。 短 task 里,模型足够强也许能自评。Long-run task 里,context rot 让自评的 bias 指数级放大。
- Graceful degradation 是结构性的。 任何系统长时间运行都需要容错。这是分布式系统的基本功。
唯一会消失的是具体的 failure mode 补丁——某个模型容易犯的特定错误。但控制框架本身不会消失。
上一篇的结尾是:别期望 AI 行为正确。构造一个结构,让它想不正确都难。
这篇的补充是:当 task 变长,结构本身也需要是活的。
不是设计一个完美的静态约束,而是运营一个持续演化的控制系统。从 “构造结构” 升级为 “运营结构”。
Harness engineering 不是一次性的设计工作。它是一个持续的工程实践——就像你不会只在上线那天看一眼 monitoring dashboard 然后关掉。