上一章我们武装了一支 AI 团队——spawn vs delegate、显式路由、并行冲突管理。但拥有团队只是起点。一支装备精良的团队如果每一步都需要指挥官拍板,它的吞吐量仍然受限于指挥官的注意力带宽。这一章解决的问题是:怎么让这支团队自主运转,而你只在关键节点介入?
三个阶段:Micro-Management → Macro-Delegation → Autonomous Operation
大多数人用 AI 写代码的方式是这样的:写一句 prompt,等 AI 吐出一段代码,肉眼审一遍,不满意就再改 prompt。一来一回,一个下午过去了,产出大概相当于一个中等水平程序员一小时的活。
这不是 AI-native 工作方式。这是把 AI 当 Stack Overflow 用。
我经历了三个阶段,每个阶段之间有一道认知门槛。
第一阶段:Micro-Management。 每一步都盯着。写个函数,审一遍;改个 bug,审一遍;加个测试,审一遍。人是瓶颈,AI 是打字机。这个阶段的 token 效率大约是 1:1——你花多少时间看,AI 就干多少活。
第二阶段:Macro-Delegation。 你学会了把任务打包。不是”帮我写个函数”,而是”这个 module 的 spec 在这里,帮我实现,包含测试和错误处理”。你开始信任 AI 能在一个较大的范围内自主决策。token 效率跳到 1:5 甚至 1:10。
第三阶段:Autonomous Operation。 你不再一个一个任务地喂。你设计一条 pipeline,让 AI 自己拆解计划、执行、验证、迭代。你的角色从 operator 变成 architect + reviewer。这个阶段,一个人可以在 90 分钟内完成 21 个 work unit——不是因为你打字更快了,而是因为你不在 loop 里了。
这三个阶段是能力递进的关系:你先学会驾驭单个 AI(前两章的 protocol 和 harness),然后学会协调多个 AI(第三章的 multi-silicon),最后才有条件让整个系统自主运转(autonomous operation)。每一层都是下一层的前提。
一个人之所以能成为一支团队,不是因为 AI 变强了,而是因为你学会了不挡路。
OPC:一个人的流水线
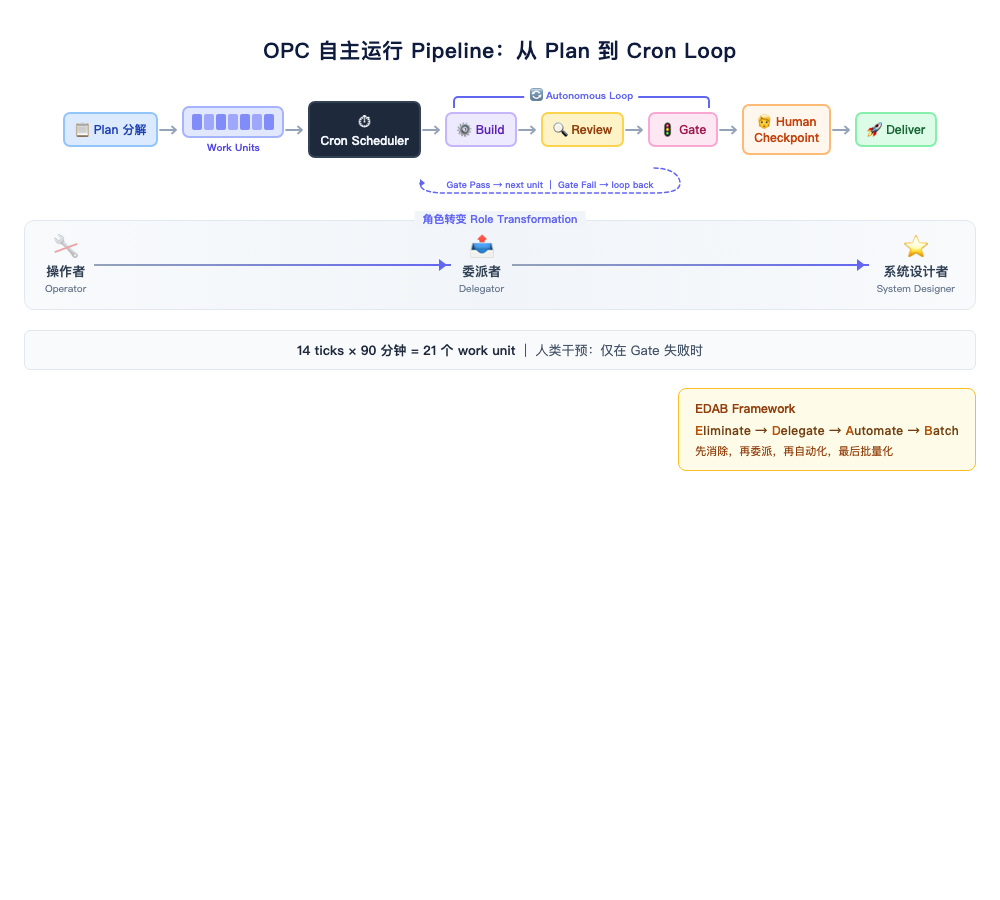
OPC(One-Person Company)不是一个浪漫的概念,它是一个工程问题:一个人怎么把自己变成一条 pipeline?
传统软件团队的 pipeline 大概长这样:
PM 写 spec → 工程师实现 → QA 测试 → Tech Lead review → 部署五个角色,至少三天。在 OPC 里,这条 pipeline 压缩成:
你写 spec → AI 实现 → AI 测试 → AI review → 你做最终决策 → AI 部署一个人,但你不是在做所有人的活。你只做两件事:定义问题 和 做最终决策。中间的实现、测试、review 全部委托给 AI。
换个说法:OPC 的本质是一个建筑师管理一支砌砖机器人团队。
Coding agent 带来的真正转变不是”写代码更快”,而是角色的根本重定义——你从执行者变成了设计者。砌砖工关心的是每块砖放得正不正,建筑师关心的是这面墙该不该存在。当 AI 承担了砌砖的工作,“编程”这件事没有消失,但你学的不再是语法和 API,而是逻辑分解能力——怎么把一个模糊的目标拆成 AI 能独立执行的清晰任务。
这意味着开发变成了异步协作。你不再手把手写函数,你给 agent 的是任务而不是问题。“帮我优化这个页面性能”是问题,“把首屏 LCP 降到 2.5 秒以内,方法限定为图片懒加载和 CSS 关键路径提取”是任务。前者 agent 会来回问你十次,后者 agent 可以独立跑完。
OPC 时代,每个人都在变成 CTO。不是因为你懂了更多技术栈,而是因为你在做的事情和 CTO 本质上一样:定义架构、分配资源、做 go/no-go 决策。唯一的区别是你的”团队”是硅基的。
这里有一个关键的架构缺失,我在实践中踩过坑:从 plan decomposition 到 auto-termination 之间缺一层。什么意思?AI 可以把一个大任务拆成小任务(plan decomposition),AI 也可以判断一个小任务是否完成(completion check)。但是,AI 不擅长判断 “整体是否已经收敛到可以停下来”。
这不是 AI 的智力问题,这是一个 feedback loop 设计问题。当你把 decomposition、execution、verification 全部自动化之后,你需要一个显式的 termination condition。否则 AI 会在已经足够好的方案上继续打磨,或者在一个死胡同里反复尝试。
我的解决方案很朴素:给每个 autonomous loop 一个 tick budget。14 ticks 能做多少事,就做多少事。到了就停。人类 review 整体结果,决定是否启动下一轮。
这个 gap 是真实存在的。如果你想做 24 小时级别的 autonomous operation,plan decomposition → execution → verification → convergence check → auto-termination,这条链上的每一环都得可靠。目前的 LLM 在前三环表现不错,但 convergence check 仍然需要人在 loop 里——至少在 2026 年的今天是这样。
Iterative Review:Devil’s Advocate 的价值
Review 的必要性和 independent review 的机制,前两章已经充分论证。这里不再重复”为什么要 review”,而是分享一个在 OPC pipeline 中额外有效的模式:多轮 review amplification。
具体来说,在标准的 correctness review(Round 1)和 robustness review(Round 2)之后,加一轮 Devil’s Advocate(Round 3)。注意:这里的 Devil’s Advocate 是独立的 subagent(spawn 一个新 session),不是第二章批评的 same-session persona。区别至关重要——独立 session 没有前序 context 的锚定效应,能真正从对立面审视。指令很简单:“你的任务是干掉这个设计。找到一个理由证明这个方案从根本上是错的。”
关键在于每一轮的 prompt 都包含前几轮的 findings——信息不丢失,视角在累积。
大多数时候,Round 3 找不到致命问题——这恰恰证明了前两轮的有效性。但在我的实践中,Round 3 确实干掉过一个差设计。那个设计在 correctness 和 robustness 两轮都通过了,因为它在技术上是正确的、在 edge cases 上是健壮的。但 devil’s advocate 视角发现了一个根本性问题:这个设计解决的是一个不应该存在的问题。上游的数据模型如果调整一下,这整个 module 都不需要存在。
没有 Round 3,这个设计会被实现、被测试、被部署,然后在三个月后的重构中被整体删掉。
三轮 review 的成本大约是单轮的 3-4 倍 token,但增量视角带来的缺陷检出是非线性的。这个方法同样适用于非代码内容——文档、pitch deck、技术博客。让 AI 分别从不同角色审同一篇文章,交叉信号(多个角色同时标记的问题)是最高优先级。
Cron Loop:自动化的产品迭代
Iterative review 解决的是质量问题。但 OPC 还有一个更大的问题:迭代速度。
传统团队的迭代节奏是以周为单位的。周一 planning,周五 demo,中间五天写代码。一周一个 iteration。如果你是一个人,按这个节奏,你永远追不上一个五人团队。
我的解决方案是 cron loop:把产品迭代变成一个自动化的循环,每 30 分钟一个 cycle。
但在讲具体流程之前,有一个更根本的问题:cron loop 每轮识别出一堆问题,怎么决定做哪些、不做哪些?
答案是 EDAB 框架——Eliminate → Delegate → Automate → Batch。注意顺序:这是一个漏斗,每一步都在减少下一步的输入量。
E(消除): 第一步不是优化执行,而是质疑存在。这个任务真的需要做吗?如果上游设计调整一下,这个 bug 根本不会出现——那正确的做法是改上游,不是修 bug。跳过 E 直接搞 A(自动化),就是在高效地做不该做的事。
D(委托): 消除不了的,能不能交给 AI 自主完成?大部分 cron loop 里的问题——UI 修正、测试补全、文档更新——天然适合委托。
A(自动化): 需要人参与但可以模板化的,写成 script 或 prompt template,下次自动执行。
B(批处理): 实在需要人工决策的,攒到一起批量处理,减少 context switch。
OPC 每天面对海量决策,EDAB 是优先级裁剪的利器。没有这个漏斗,你的 cron loop 会变成一台没有筛子的流水线——什么都处理,效率反而更低。
一个 cycle 的流程就是 EDAB 的实例化:
走查当前状态 → 识别问题 → EDAB 裁剪 → 并行实施(AI 执行) → 验证 → 收敛30 分钟。不多不少。如果一个问题 30 分钟解决不了,它会被拆成更小的问题进入下一个 cycle。
这个 loop 的关键设计决策是 并行实施。在一个 cycle 里,AI 不是串行地一个接一个修问题,而是同时处理多个独立的修改。这在技术上很简单——开多个 session 就行。但在认知上需要一个转变:你不再逐个审查每个修改,你审查的是 整体状态的变化。
一个真实的数据点:5 轮 cron loop,总共 150 分钟,完成了一个产品从 “勉强能用” 到 “可以给用户看” 的跨越。5 轮迭代涵盖了 UI 修正、API 重构、错误处理、文档更新和性能优化。
但有一个重要的观察:后期递减是正常的。
前两轮 cron loop 的产出最高,因为低垂的果实最多。第三轮开始,每轮的 marginal improvement 明显下降。到第五轮,你修的基本都是 polish 级别的问题。
这不是系统出了问题,这是收益递减的自然规律。正确的做法不是继续跑第六轮、第七轮,而是 停下来,重新定义问题。也许产品需要的不是更多 polish,而是一个新 feature。也许 UI 已经够好了,瓶颈在 onboarding flow。
Cron loop 给你的是速度。但速度本身不是目的。知道什么时候停下来,比跑得快更重要。
诚实的能力边界:什么还做不到
我见过太多 AI 布道师,说什么 “AI 可以替代整个工程团队” “一个人顶十个人”。这些话在特定条件下是对的,但如果你真信了,你会在最痛的地方摔跤。
让我给你一个诚实的数据点。
我跑过一次 24 小时 autonomous operation 的边界测试。不是 demo 级别的,是真实产品、真实代码库、真实复杂度。结果:5 个 reviewer(不同角色、不同视角)在 24 小时 autonomous 产出中找到了 14 个 bug。样本量是单次实验,不具备统计显著性,但方向性结论是清晰的。
14 个。不是 14 个 typo,是 14 个会影响用户的 bug。包括:
- 逻辑错误:条件判断写反,导致 edge case 下的错误行为
- 集成问题:两个独立实现的 module 在接口上的假设不一致
- 遗漏:spec 里明确要求但实现中被跳过的功能点
- 回归:修一个 bug 的同时引入了另一个 bug
这些不是 AI “不够聪明” 导致的。这些是 autonomous operation 在长时间运行时必然会出现的问题。原因很清楚:
- Context drift。 随着 conversation 变长,AI 对早期决策的记忆会退化。它不会忘记——context 还在——但它的注意力会偏向最近的内容。
- Error compounding。 在 supervised mode 下,人类会在每一步抓住小错误。在 autonomous mode 下,一个小错误会传播到后续步骤,被当作正确的前提继续构建。
- Specification gap。 再好的 spec 也有没写到的地方。在 supervised mode 下,人类会用常识补上这些 gap。在 autonomous mode 下,AI 要么猜(经常猜错),要么跳过(留下隐患)。
这些数据告诉我几件事:
第一,autonomous operation 的时间尺度目前以小时计,不以天计。 90 分钟内完成 21 个 work unit,质量可控。24 小时无监督运行,质量不可控。这个边界在 2026 年还没有被突破。
第二,reviewer 的数量和多样性比 AI 本身的能力更重要。 5 个 reviewer 找到 14 个 bug,不是因为每个 reviewer 都很厉害,而是因为他们看的角度不同。交叉检测的效果远超单一视角的深度审查。
第三,不要在 root cause 没修的时候跑 eval loop。 这是我花了真金白银学到的教训。有一次我发现 AI 产出的代码有一个系统性的问题——不是偶发的 bug,是一个 prompt 设计上的缺陷导致的 pattern。我当时的选择是:先跑一轮完整的 eval loop,量化问题的严重程度,然后再修。
结果:23M tokens,约 $162(基于当时的 LLM 定价,具体成本因模型和时间点而异),全部浪费。
因为 eval loop 的每一轮都在评估一个 已知有缺陷的系统。评估结果只会告诉你 “是的,它确实有问题”——但你已经知道它有问题了。正确的做法是 先修 root cause,再跑 eval。这看起来是常识,但当你被 autonomous operation 的惯性裹挟时,“先让系统跑起来再说” 是一个极其诱人的陷阱。
$162 不多。但它教会我一个原则:autonomous 不等于 unattended。你可以让 AI 自己跑,但你不能不看方向。
实战:从 10-check spike 到 npm-publishable 的 14 ticks
让我讲一个完整的实战案例。
任务:把一个内部的 CLI 工具从 “能跑” 变成 “能发 npm”。具体来说,就是从一个 10 个 check 都没过的 prototype,变成一个 test coverage 充足、文档完整、CI 绿灯、可以 npm publish 的 package。
我用 OPC loop protocol 跑这个任务。14 ticks,90 分钟,21 个 work unit 完成。
逐 tick 记录:
Tick 1-3:基础设施。 修 CI pipeline,补 tsconfig,配 ESLint。这些是 AI 最擅长的工作——模式化、规则明确、不需要创造性判断。3 个 tick,6 个 work unit。
Tick 4-7:核心功能修复。 10 个 failing check 里有 4 个是逻辑错误。AI 逐一修复,每修一个跑一次完整的 test suite 确认没有 regression。4 个 tick,5 个 work unit。
Tick 8-10:测试补全。 原始 prototype 的 test coverage 大约 30%。这三个 tick 把它拉到 85%。AI 写测试的效率非常高,因为它可以从实现代码直接推导出需要覆盖的 case。3 个 tick,5 个 work unit。
Tick 11-13:文档和 packaging。 README、CHANGELOG、package.json 的 metadata、npm publish 的 prepublish script。3 个 tick,4 个 work unit。
Tick 14:最终验证。 跑完整的 CI pipeline,确认所有 check 通过。dry-run npm publish,确认 package 结构正确。1 个 tick,1 个 work unit。
几个观察:
Work unit 的分布不均匀。 前 3 个 tick 完成了 6 个 unit(均值 2.0),中间 7 个 tick 完成了 10 个 unit(均值 1.4),最后 4 个 tick 完成了 5 个 unit(均值 1.25)。递减曲线清晰可见。
Tick 的时间不均匀。 基础设施的 tick 大约 4-5 分钟一个(AI 执行快,决策简单)。核心功能修复的 tick 大约 7-8 分钟一个(需要理解上下文,可能需要多次尝试)。最终验证的 tick 最长,大约 10 分钟(等 CI 跑完)。
14 ticks 是否足够? 对这个规模的任务,足够了。但如果任务更大——比如从零构建一个完整的 SaaS——14 ticks 只够完成 scaffolding。要测试 24 小时级别的 autonomous operation,需要更大的任务。 这也是为什么我说当前的能力边界是 “小时级” 而不是 “天级”。
这个案例的意义不在于 “90 分钟发了个 npm 包”。意义在于:整个过程中,我没有写一行代码。 我写了 spec,我做了 tick 之间的优先级决策,我做了最终验证。但实现、测试、修复、文档——全是 AI 做的。
这就是 autonomous operation 的含义。不是 AI 自己在跑,是你设计了一个系统,AI 在这个系统里自己在跑。
效率的阴影:当 Agent 杀死摩擦
写到这里,我需要诚实地面对一个不舒服的问题。
前面整章都在讲效率——cron loop 的速度、parallel execution 的吞吐、EDAB 的裁剪。但人类最伟大的创造,几乎没有一个来自高效的流水线。它们来自绕路、对抗、摩擦。
达芬奇画《最后的晚餐》用了三年,中间大量时间在”浪费”——盯着墙壁发呆、和修道院院长吵架、跑去研究光学。如果给达芬奇一个 cron loop,30 分钟一个 cycle,他可能会更快地画完一幅画,但那幅画不会是《最后的晚餐》。
AI 提升效率的方式,本质上是消除摩擦。 但创造力需要摩擦作为燃料。当你手动调试一个 bug 两小时,你对系统的理解会深入到 AI 帮你秒修时永远达不到的层次。当你和同事为一个架构决策争论半天,最终方案的质量远超任何一个人独立思考的结果。
OPC 模式下,你不再和人争论,不再手动调试,不再被迫在限制条件下创造性地解决问题。一切都被优化掉了。效率上去了,但某种东西也丢失了。
AI 原生组织面临的最深层挑战不是技术性的,而是哲学性的:当 agent 承担了所有执行层面的摩擦,人必须主动制造新的摩擦。
怎么制造?几个实践:
- 故意不用 AI 做某些事。 每周留出固定时间手写代码、手画架构图。不是因为效率更高,而是因为手工过程中的”低效”正是深度思考发生的地方。
- 设置 Devil’s Advocate 不是为了找 bug,而是为了制造冲突。 前面讲的 Round 3 review,其深层价值不在于找到技术缺陷,而在于强迫你从对立面重新审视自己的假设。
- 定期”退化”。 关掉 autonomous loop,回到 micro-management 模式,亲手走一遍完整流程。你会发现新的 insight,因为你重新接触了被自动化遮蔽的细节。
这不是怀旧,不是反技术。这是一个工程化的认知策略:在 AI 优化掉的摩擦中,识别哪些是纯粹的浪费(应该消除),哪些是创造力的燃料(应该保留甚至放大)。
效率和创造力的张力,是 autonomous operation 的永恒议题。不要假装它不存在。
本章小结
这一章的核心论点可以压缩成三句话:
1. Autonomous operation 是工程问题,不是智力问题。 OPC loop 的 tick budget、cron loop 的固定 cycle、iterative review 的视角叠加——这些都是可设计、可调参、可复现的 pipeline。AI 不需要”更聪明”才能自主运转,你需要更好的系统设计。
2. 放大效应的杠杆点是并行和结构,不是速度。 一个人 90 分钟完成 21 个 work unit,不是因为 AI 打字快,而是因为并行执行消除了串行等待,结构化的 review 视角替代了重复的单点审查。速度是结果,不是原因。
3. 边界意识是 autonomous operation 最重要的能力。 小时级可控,天级不可控。知道什么时候停下来比跑得快更重要——无论是 cron loop 的收益递减,还是 $162 eval loop 的沉没成本。Autonomous 不等于 unattended。
下一章,我们把视角从个人拉到市场。如果 autonomous operation 是个人的能力放大器,那 agent 时代的创业机会在哪里?剧透:不在你以为的地方。