
你写过多少文档,最后真的有人看?
我写过不少。Onboarding guide、API spec、deployment runbook、architecture decision record。写完的那一刻是最准确的——然后就开始腐烂。代码改了,文档没跟上。新人问问题,老人说「别看那个文档,过时了」。
文档是 write-once-read-maybe-update-never。
这不是执行力问题,是结构性问题。文档和代码住在不同的地方,由不同的人在不同的时间维护。drift 是必然的。
Skill 不是「更好的文档」
如果你用过 Claude Code 的 Skill,可能觉得它就是一种 prompt template——一个 markdown 文件,告诉 agent 怎么做某件事。
表面上是这样。但 Skill 和文档有一个本质区别:
文档是给人读的。Skill 是给 agent 执行的。
这个区别改变了一切。文档写完就死了,因为没人有动力去 update。但 Skill 每次被执行时都在接受验证——agent 跑不通,你马上知道它过时了。
更准确的说法:Skill 是 human-agent contract 的持久化形式。
三个属性让它区别于任何形式的文档:
- Explicit — 白箱可审计。不是藏在某个 model 记忆里的隐式行为,而是一个你能
cat出来看的文件 - Portable — 纯文本,跨 agent 可用。Claude Code 的 Skill 可以被任何支持 markdown 的 agent 理解
- Auditable — 版本控制 + governance。
git log告诉你每次改动是谁、什么时候、为什么
你可能会说:这不就是 Jupyter Notebook / Infrastructure as Code / doctest 吗?
不一样。那些是给 deterministic executor 的指令——Python 解释器、Terraform、pytest。Skill 是给 stochastic agent 的意图声明。Agent 理解 intent,自己决定 how。
一个 deployment Skill 不会写 ssh user@server && docker pull ...。它会写 “部署到 staging 环境,确保数据库 migration 先跑完,health check 通过后再切流量”。Agent 根据当前环境自己决定用 ssh 还是 kubectl 还是 Terraform。
Skill 是 intent,不是 procedure。
「第二大脑」这次不一样
你可能想到了 Notion、Obsidian、Roam Research 这些「第二大脑」工具。它们的承诺是一样的:把你的知识结构化、可检索、可复用。
问题是:codification 是苦差事。
写一张高质量的笔记卡片需要 10-30 分钟。整理链接、提炼 insight、维护结构。大多数人坚持不了三个月。GTD、Zettelkasten、PARA——方法论不缺,缺的是执行力。
这次不一样,因为写的人变了。
不是人写 Skill 给 agent 用。是 agent 写 Skill,人做 curation。
我的 memex 系统就是这样工作的:agent 做完一个任务,自动把学到的教训提炼成卡片。我只需要扫一眼,决定保留还是删除。Skill 同理——agent 在执行过程中发现 pattern,自动提炼成 Skill 文件,我审批。
人的角色从 author 变成了 curator。
Friction 下降一个数量级。不是 “我要抽 30 分钟写这个”,而是 “agent 写了这个,我花 30 秒看一眼”。Codification 的失败率从 90% 降到了可以忽略。
这是范式变了,不是工具变了。
为什么 Skill Marketplace 必然失败
既然 Skill 这么有用,是不是应该有个 marketplace 让大家买卖?
不会成立。三重否定。

Supply side: reproduction cost ≈ 0。 Skill 是 plain text。看一遍就能复制。没有编译产物、没有运行时依赖、没有 DRM。你无法对一个 markdown 文件收费——就像你无法对一个 shell script 收费一样。
Demand side: agent 替代了 curation。 传统 marketplace 的价值是帮你发现和筛选。但当你的 agent 能理解你的 intent、自动 fork 一个开源 Skill、适配你的 context——你为什么还需要逛商店?Agent-assisted fork 比人工浏览更精准。
Coupling: 三层不可移植。 Environment(你的 OS、工具链)、version(agent 版本、API 版本)、context(你的项目结构、团队约定)——三层耦合让一个 Skill 几乎不可能开箱即用。Shell script marketplace 不存在,Skill marketplace 同理。
还需要实证吗?GPT Store。 OpenAI 有 1 亿用户、最强分发渠道、最大开发者生态。结果 GPT Store 成了 “概念验证失败” 的教科书案例。不是执行力不够——是这个模型在结构上就不成立。
唯一可能的例外:SaaS-bound skills(绑定特定平台 + 数据 + runtime 的垂直场景)和 enterprise internal governance(企业内部统一的 Skill 治理)。但这不是 marketplace,这是 platform lock-in 和 internal tooling。
Fork 即流动
如果 marketplace 不成立,Skill 怎么流动?
Fork。
Skill 是 value object——fork 就是 own。不像 SaaS 需要账号、不像 API 需要 key。cp skill.md my-skill.md,它就是你的了。
但 fork 的真正价值不是「复制粘贴」。
Decision trace inheritance — fork 一个 Skill 时,你继承的不是 “这段代码做什么”,而是 “为什么做这个选择”。一个好的 Skill 会在注释里写清楚 trade-off:“用 streaming 而不是 batch 是因为我们的数据量超过内存限制”、“选 JWT 而不是 session 是因为需要跨服务无状态验证”。
这些 decision trace 是 Skill 最值钱的部分。新人 fork 你的 Skill 不是为了抄代码,是为了继承你的判断力。
Agent-assisted fork 是杠杆。 你不需要手动改 Skill。告诉 agent “把这个 deployment Skill 适配到我们的 k8s 环境”,agent 理解 intent → 分析你的 context → 自动重构。这比任何 marketplace 的 “一键安装” 都强。
实际上,Skill 可以分三层:
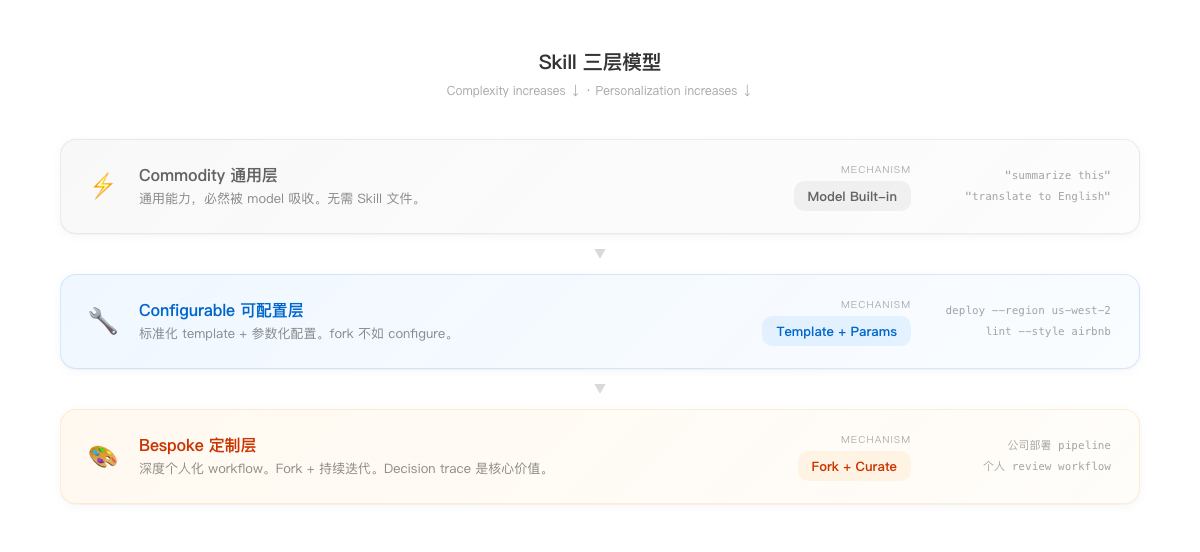
- Commodity 通用层 — “summarize this”、“translate to English”。这些能力必然被 model 吸收,不需要 Skill 文件
- Configurable 可配置层 — 标准化 template + 参数化配置。
deploy --region us-west-2、lint --style airbnb。Fork 不如 configure - Bespoke 定制层 — 你公司的部署 pipeline、你个人的 review workflow。深度个人化,Fork + 持续迭代。Decision trace 是核心价值
大多数人需要的 Skill 分布在第二和第三层。第二层靠社区开源就能解决(Anthropic 的 skill-creator + 大量开源 Skill 提供 70 分起点),第三层靠自己迭代——agent 帮你从 70 分做到 90 分。
冷启动从来不是问题。迭代才是。
安全:不是不可解,是 ROI 算不过来
外部 Skill 有没有安全问题?有。而且比你想的严重。
三类威胁:
- Tool poisoning — Skill 里的 prompt 劫持 agent 行为,让它执行未预期的操作
- Rug pull — Skill 作者在 update 中植入恶意指令(你已经信任了这个 Skill,不会每次都审计)
- Description shadowing — Skill 的 description 和实际行为不一致,欺骗 agent 的工具选择
这不是传统的 web 安全问题。NL(natural language)API surface 比 REST API 更难做 static analysis。你没法用 linter 扫一个 markdown 文件里的 “恶意 intent”。
解法存在吗?存在。Sandbox execution、capability-based permission、runtime behavior monitoring。但这些基础设施的投入只在 enterprise 场景 值得——大企业有合规要求、有安全团队、有预算。
对个人开发者?真正的安全模型是 local-first:
你控制文件 > 你信任平台 > 你信任作者
你的 Skill 就是你本地的 markdown 文件。你能看到每一行。你用 git 管版本。不需要信任任何 marketplace 的审核流程。
这也是 Skill marketplace 的另一个死因——安全投入的 ROI 在去中心化模式下根本算不过来。
知识在循环中活起来
说了这么多 Skill 的属性、marketplace 的失败、fork 的价值、安全的 trade-off——核心到底是什么?
知识的流动。
不是 marketplace 里的商品流动——那是错误的比喻。是认知在一个循环中不断精炼:
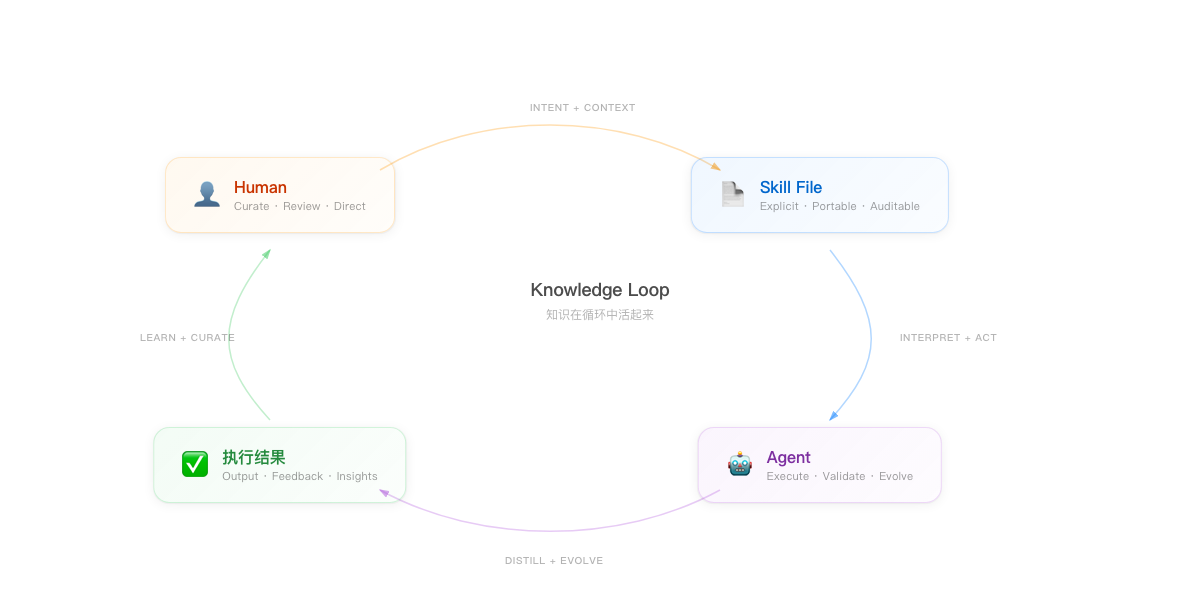
Human → Skill File → Agent → 执行结果 → Human
- 人有 intent 和 context,写进 Skill(或者让 agent 写)
- Agent 读 Skill,理解 intent,执行任务
- 执行结果产生反馈——成功或失败
- 人 review 结果,curate Skill——修正、补充、删除
- 下一次循环,Skill 更准确
每次循环,知识都在进化。 文档做不到这一点,因为文档不参与执行。Skill 做到了,因为它是 agent 执行的输入,执行结果是 Skill 进化的反馈。
这就是 “流动” 的真正含义。不是 Skill 在人与人之间流通(那是 marketplace 叙事),而是知识在 人→agent→执行→反馈 的循环中活起来。
每个人都会拥有自己的 Skill library。不是一次性购买的,是在日常工作中不断积累的。Agent 写初稿,你做 curator。三个月后回头看,你的 library 就是你的第二大脑——但这次是真的活的。
写在最后
对平台方的一个警告:把 Skill 吸收进 proprietary memory 是短期 lock-in 策略。长期看,portable format 一定赢。历史已经证明过了——proprietary document format 输给了 plain text + markdown + open standard。Skill 也会走同样的路。
对你的建议:别预测未来,去用。
从今天开始,让你的 agent 帮你写第一个 Skill。
三个月后看看你的 library 长成什么样。
The structure of the next era won’t be discovered — it’ll be built.