The Agent Era Is Not About Removing the GUI
Chapter 4 covered how one person turns themselves into a pipeline — OPC, cron loops, iterative review — personal-level force multipliers. But once the pipeline is built, what product do you build with it? What market do you aim at?
This chapter zooms out from the individual to the industry. Even if you have no plans to start a company or raise funding, the framework here is equally critical for technology choices and career direction. You don’t need to be a founder to understand the layering logic of infrastructure vs. application — choosing which company to join, which tech stack to bet on, which architecture to use for a side project all rest on the same judgment framework. If business analysis isn’t your thing, feel free to skip straight to Chapter 6’s engineering field notes — that’s pure war stories from the trenches.
Every few years, the tech world collectively makes the same mistake: reducing a “new paradigm” to “removing some part of the old paradigm.”
When mobile came along, people said “it’s just shrinking web pages to fit a phone screen.” When cloud computing arrived, people said “it’s just running your servers in someone else’s house.” Now the agent era is here, and the dominant narrative is: “Remove the GUI and let AI operate directly.”
This is wrong. Not a little wrong — directionally wrong.
Removing the GUI is a UI-level change. It assumes the problem is “humans have to manually click buttons,” and the value of agents is “AI clicks buttons for you.” If you build a product on this logic, you’ll end up with traditional screen-coordinate-based RPA (Robotic Process Automation) — a brittle automation script that breaks the moment the underlying UI changes.
The correct agent-native approach is to reinvent the interaction model, not remove it.
Three design principles:
Plugin > Standalone. An agent doesn’t need a standalone application. An agent needs callable capabilities. If you’re building a product for the agent era, first ask yourself: can an agent invoke it as a tool? If not, your architecture is wrong. The rise of MCP (Model Context Protocol) is no accident — it provides a standardized protocol for exposing tools and resources, letting “applications” be discovered and invoked as “capabilities” by agents. That’s the right abstraction for agent-native.
Specific > Platform. “Build an agent platform where all agents can run” sounds sexy, but it’s classic engineer-brain thinking. The money isn’t in the platform — it’s in the specific tools on the platform that solve concrete problems. You don’t need to build “the operating system for agents.” You need to build “the specific tool agents use when doing code review.”
Observability > Auto-fix. Most teams chase “let the agent auto-fix problems.” But the real need is “let humans understand what the agent is doing.” When agent operation chains grow long — ten steps, twenty steps, hundreds of steps — observability matters more than auto-fix. Because before you trust auto-fix, you first need to understand the agent’s behavior. Auto-fix without observability is a black box, and black boxes are nightmares in production.
All three principles point to the same conclusion: the opportunity in the agent era is at the infrastructure layer, not the application layer.
Infrastructure Layer > Application Layer
Why infrastructure, not application?
An analogy. In the early days of mobile, the companies that ultimately made the real money weren’t the ones building apps (though some apps did make money) — they were the ones building infrastructure: Stripe let apps accept payments, Twilio let apps send text messages, AWS let apps deploy. Apps came and went; infrastructure got more deeply embedded over time.
The agent era follows a strikingly similar pattern:
-
Application layer: Build an “AI writes your emails” app. Build an “AI books your flights” agent. These products have a problem: the moat is paper-thin. Any LLM provider can turn your feature into a built-in capability in the next release. Your product is a prompt wrapper on top of an LLM.
-
Infrastructure layer: Build memory systems for agents. Build tool registration and discovery protocols. Build an observability platform for agent operations. Build communication and coordination layers between multiple agents. The moat for these products is systemic complexity — not something a prompt can replace.
A simple litmus test: If the next frontier model drops and your product becomes obsolete, you’re in the application layer. If that same day your product becomes more useful, you’re in the infrastructure layer.
The stronger the LLM, the more infrastructure is needed — more memory, more complex tool integrations, finer-grained observability, more reliable orchestration. That’s the structural advantage of the infrastructure layer.
But “infrastructure vs. application” is too coarse a dichotomy. To see where the real opportunities lie, you need a finer-grained map.
The AI Industry Value Chain: The Smile Curve
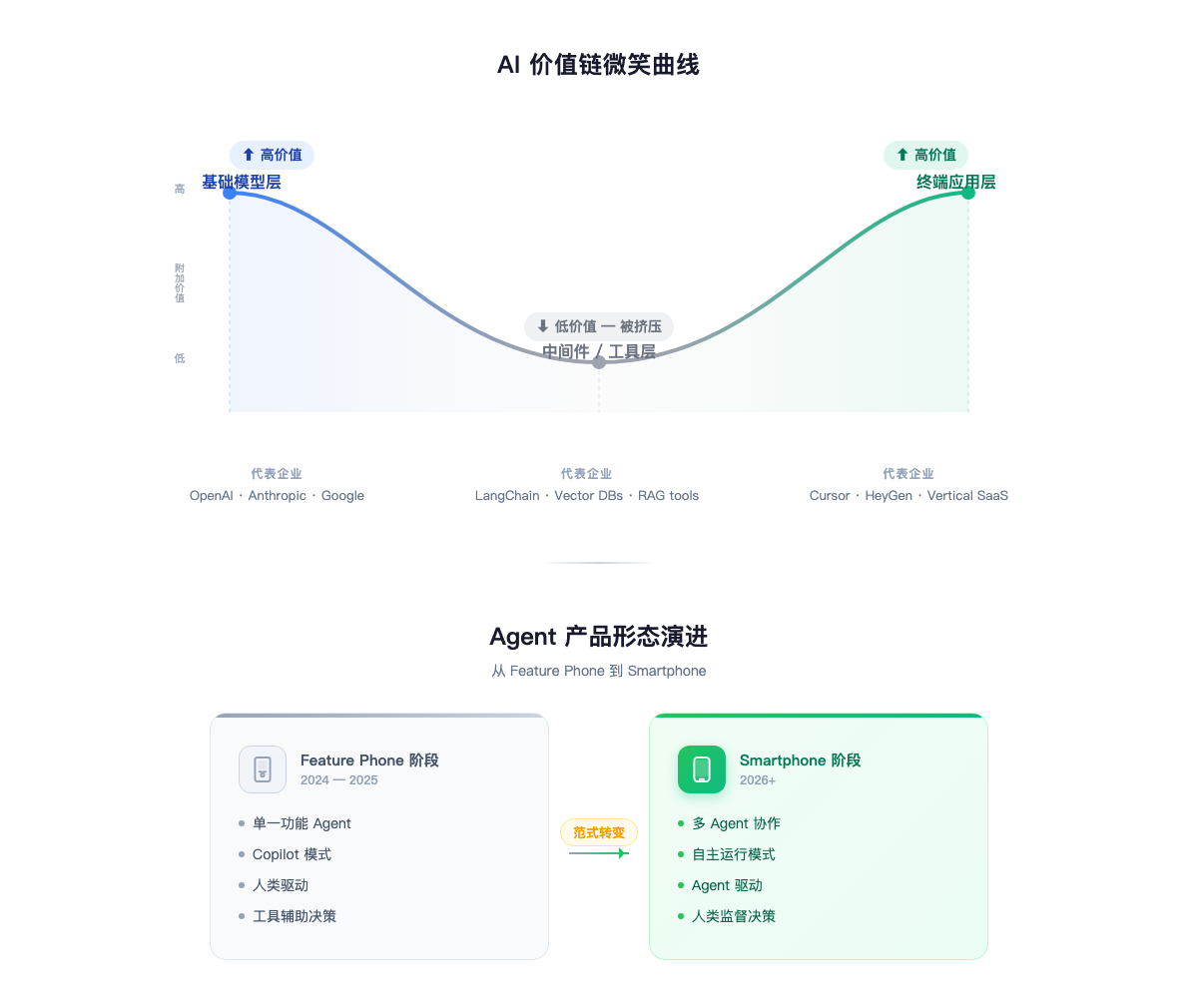
If you plot a profit curve across the AI industry, the shape looks like a smile — high at both ends, low in the middle.
Upstream: Infrastructure. GPUs, cloud computing, training clusters. NVIDIA’s gross margins exceed 70%; cloud providers are flush with revenue from AI compute demand. This is a capital-intensive game where barriers are scale and physical-world scarcity.
Midstream: Foundation models. GPT, Claude, Gemini, DeepSeek. The highest technical sophistication, but the most compressed margins. The reason is straightforward: model capability convergence is happening far faster than anyone expected, and the open-source community (especially DeepSeek’s distillation approach) keeps driving down the cost of accessing frontier-level capabilities. Competition in the foundation model layer is turning into a war of attrition — everyone is strong, nobody is making money.
Downstream: Vertical applications. This is where margins recover. Cursor reportedly crossed $100M ARR in roughly two years, with growth still accelerating. It’s not building a “general AI IDE” — it’s building “the AI workflow for developers,” a product deeply embedded in a vertical use case. The value of vertical applications isn’t in the model itself; it’s in the depth of understanding of the user’s workflow and the ability to productize that understanding.
The smile curve tells you one thing: if you have neither NVIDIA’s capital barriers nor deep vertical domain expertise, getting stuck in the middle building generic model-layer tools means you’ll be squeezed from both ends. Either go upstream into infrastructure (requires massive capital) or go downstream into vertical applications (requires deep domain know-how). The middle is the most uncomfortable place to be.
This also refines the earlier “infrastructure > application” claim — more precisely: deep vertical applications and foundational infrastructure both have value. What doesn’t have value is shallow, generic applications.
Product Form Evolution: Feature Phone vs. Smartphone
If the smile curve tells you “where to fight,” product form determines “what weapons to use.”
Current AI products come in two basic forms. I’ll borrow a mobile industry analogy to distinguish them:
Feature Phone mode: Integrate AI capabilities into an existing product. Monica aggregates multiple model APIs into a unified assistant. Notion added AI writing features. Gmail added AI summaries. The core logic is bolting an AI module onto an existing framework — the user experience doesn’t fundamentally change; certain steps just get faster.
Smartphone mode: Make AI the core interaction paradigm of the product. Cursor isn’t “VS Code with an AI plugin” — it redefined how developers interact with code. AI is in the loop, not in the sidebar. Manus lets AI agents autonomously execute multi-step tasks — the user provides the goal, the agent finds the path. The core logic is redesigning the entire product around AI capabilities.
This analogy has limits — in mobile, Feature Phones were replaced by Smartphones, but in AI products the two forms may coexist long-term. The reason is simple: not every use case needs Smartphone mode. Adding an AI formula assistant to Excel (Feature Phone) and building an AI-native data analysis tool (Smartphone) solve problems at different levels and serve users at different stages.
A deeper evolution is underway: from App Store to Agent Marketplace.
The traditional app marketplace is standardized — each app provides fixed features, humans interact via GUI. Agent marketplace logic is fundamentally different:
- From standardized to customized. Agent capabilities can be composed on demand; you no longer “download an app to get all its features.”
- From human interface to machine interface. Agents discover and invoke other agents’ capabilities without a GUI — what’s needed is standardized APIs and protocols (this is where MCP’s value lies).
- From persistent installation to ephemeral invocation. You don’t “install” an agent; you invoke its capability when needed, and it’s gone when done.
But for an Agent marketplace to actually work, four core problems need solving: Connection (how does an agent discover other agents’ capabilities?), Incentives (how do capability providers get rewarded?), Trust (how do you ensure the invoked agent won’t screw up?), Cold start (how do you spin the flywheel when both sides of the marketplace are empty?). Each of these four problems is a startup opportunity.
The Defensive Paradox: Stronger Models, Weaker Moats
There’s a counterintuitive phenomenon in the industry landscape that deserves its own discussion: the defensibility of an AI model is inversely proportional to its capability.
Traditional software logic: better product → more users → more data → even better product. A positive feedback loop where barriers strengthen over time.
AI model logic is different. Three forces act simultaneously:
- Capability rises. Each generation of models gets stronger. But this also means the bar for “building a good-enough model” is getting lower, not higher.
- Cost collapses. GPT-4-level capability cost $60/M tokens two years ago; today open-source models deliver it for nearly free. Lower cost means lower barriers to entry.
- Externality diffusion. DeepSeek proved something: the capabilities you trained for billions of dollars can be largely replicated by others through distillation at a fraction of the cost. Your investment generates knowledge spillover across the entire ecosystem.
The conclusion of all three trends combined: the model itself is not a moat. Your model leads by six months today; six months later that advantage is gone.
So where are the real moats? In everything outside the model:
- Network effects. More users → more usage data → better product experience → more users. This has nothing to do with model capability and everything to do with product ecosystem.
- Pricing power. When you’re deeply embedded in a user’s workflow, users become price-insensitive. Cursor went from free to $20/month Pro to $200/month Ultra, and paid users kept growing — because it’s become the developer’s daily operating system, with extremely high switching costs.
- Vertical data flywheels. A general model’s data advantage is easily matched, but high-quality labeled data in specific verticals (medical diagnosis, legal contracts, chip design) is extremely hard to acquire. That’s a real moat.
For founders, this means a strategic choice: don’t bet on training the best model — bet on building the deepest moat. The model is the foundation, but foundations can be swapped. Moats can’t.
But “build infrastructure” is too abstract. What specifically should you build? And more importantly — how do you evaluate whether an infrastructure idea is worth pursuing?
The “Technology in Search of a Market” Diagnostic Framework
The most common failure mode for technical founders isn’t bad technology — it’s technology in search of a market: holding a hammer and looking everywhere for nails.
I’ve seen too many projects like this: the tech demo is stunning, GitHub stars are climbing fast, but ask about monetization and things get vague. “Build great technology first, and the market will come.” No, the market won’t come to you. The market goes to whoever solves its problems, regardless of whether the solution uses AI or Excel.
To diagnose whether a tech project is worth pursuing (whether you’re investing time or money), I use three questions:
FOR WHOM?
Who is your user? Not “developers” — that’s too broad. Is it “30–100 person backend teams in the middle of breaking a monolith into microservices,” or “Series A startups deploying an LLM to production for the first time”?
The more specific your user, the clearer your product decisions. If you can’t describe in one sentence who your user is and what their number-one pain point is right now, you’re not ready to start.
WHY NOW?
Why can this problem be solved today but not last year? This question kills most “right idea, wrong time” projects.
Typical WHY NOWs for the agent era:
- LLM context windows went from 4K to 128K (some models claim 1M+ support, but actual quality in long-context tails still degrades), making previously infeasible interaction patterns viable
- Tool use / function calling went from hack to native capability
- Protocols like MCP created a standardized foundation for agent-tool integration
- Enterprise customers moved from “let’s try AI” to “we must deploy AI”
If your WHY NOW is “AI is hot,” that’s not a WHY NOW — that’s FOMO.
HOW BIG?
How large is the market? This isn’t about fabricating a TAM/SAM/SOM (Total Addressable Market / Serviceable Addressable Market / Serviceable Obtainable Market) number. It’s asking: if your product succeeds, where’s the ceiling?
An agent observability tool that every company running agents needs — its ceiling is “the infrastructure budget of every company using agents.” An “AI writes your emails” app — its ceiling is how much users will pay to save five minutes, which usually isn’t much.
Good tech ≠ worth investing in. Good tech + clear FOR WHOM + valid WHY NOW + large enough HOW BIG = worth investing in. All four conditions are non-negotiable.
Positioning Evolution from v1 to v3: A Real Case
A friend’s startup project went through three positioning iterations, and I observed the entire process up close, participating in the discussions. Same project, same underlying technology, three positioning attempts, three different fates. It illustrates how the theory above plays out in practice.
v1: “Multi-Agent Orchestration Platform”
First positioning: build a multi-agent orchestration platform. Let different AI agents collaborate like a team to complete complex tasks.
The problems with this positioning:
- Too broad. “Multi-Agent Orchestration” is a category, not a product. Investors hear this and immediately ask: “What about LangChain? CrewAI? AutoGen?” You’ve just dropped yourself into a red ocean.
- Technology in search of a market. “Multi-agent collaboration” is a technical capability, but who needs it? In what scenario is a single agent not enough and multiple agents are required? The FOR WHOM wasn’t answered.
- Architecture philosophy vs. business model contradiction. If you’re building a “platform,” your business logic should be network effects — more users make the platform more valuable. But multi-agent orchestration’s value doesn’t come from network effects; it comes from the quality of orchestration. This is a tool logic, not a platform logic.
The first time an investor stumped the founder — as my friend later described it — was vivid: the investor asked one question — “Who will be your first three paying customers?” — and he realized he couldn’t answer. No matter how well you explain the technology, that single question exposes a shaky foundation.
v2: “Agentic OS”
Learning from v1’s mistakes, the second positioning raised the level of abstraction: build an operating system for agents. Not just orchestration, but everything an agent needs to run — memory, tool management, permissions, lifecycle management.
This positioning was better than v1, but had one fatal problem:
The OS story demands lock-in, but Unix values demand modularity. If you call yourself an “operating system,” investors expect Windows/iOS-style ecosystem lock-in — developers build on your platform, users stay on your platform, switching costs are sky-high. But if your technical philosophy is Unix-style modularity and composability — every component independent, replaceable, communicating via standard protocols — that fundamentally contradicts “OS lock-in.”
You can’t simultaneously say “I’m an operating system, all agents should run on me” and “I believe in the Unix philosophy, every component is replaceable.” Those two sentences can’t appear in the same pitch deck.
This is the positioning-architecture-business contradiction: your positioning, your architecture philosophy, and your business model must be internally consistent. Any contradiction between any two will be exposed under investor scrutiny.
v3: “Cognitive Resilience Engine”
The third positioning made a fundamental shift: instead of defining the project as a category (platform / OS), it defined the specific problem it solves.
Cognitive Resilience. When an agent encounters unexpected situations, ambiguous instructions, or conflicting information, it doesn’t crash, hallucinate, or spin in an infinite loop — it degrades gracefully, seeks clarification, or falls back to a safe state. The industry hadn’t standardized on a term yet — but this precisely describes the core challenge facing production agents.
The strengths of this positioning:
- FOR WHOM is crystal clear. Any company running agents in production. Not companies playing with demos — companies that have agents operating in revenue-generating business processes. What these companies fear most is agents crashing at critical moments.
- WHY NOW holds up. In 2026, more and more companies are pushing agents from prototype to production. At the prototype stage, resilience doesn’t matter — just restart when it crashes. At the production stage, resilience is a hard requirement.
- HOW BIG is large enough. Every production agent needs resilience. This isn’t a niche market — it’s a core layer of agent infrastructure.
- Architecture and business model are consistent. A resilience engine is fundamentally middleware — it embeds into other people’s agent pipelines. This is plugin logic (plugin > standalone); no platform-level lock-in required. The business model is per-API-call pricing or per-agent-count subscription. Simple, direct, predictable.
From v1 to v3, the core change wasn’t the technology (the underlying capabilities stayed the same) — it was the narrative. v1 said “here’s what technology I have.” v2 said “here’s what category I am.” v3 said “here’s what problem I solve.” Only v3 speaks the language investors actually listen to.
There was also a subtler trap along the way: document type mismatch — answering questions with the wrong type of document. The v1 pitch deck was entirely about the technical implementation, but investors weren’t asking “how does your system work” — they were asking “who’s buying.” No amount of wordsmithing fixes this, because the document type itself is wrong. AI excels at optimizing within a document type (making your technical description more precise), but it can’t diagnose “what you’ve written isn’t a pitch deck at all — it’s a technical architecture doc.” That’s where human judgment is required.
As an aside, v1’s failure had a deeper root cause: the incumbent’s margin blind spot.
Google had better technology to do cloud computing than Amazon — but Google Cloud has been stuck in third place for years. Why? Because Google’s core business is advertising, with 50%+ gross margins. Cloud margins run 20–30%. When you’re accustomed to high-margin business, low-margin opportunities can’t win internal resources or attention. Amazon’s retail business already had thin margins, so AWS margins were “amazing” to Amazon but “why bother” to Google.
The implication for founders: incumbents’ blind spots aren’t about technology — they’re about margin expectations. If the market you’re targeting strikes incumbents as “margins too low to bother,” you naturally have a window of opportunity. The early agent infrastructure market has exactly this profile — low unit price, fragmented customers, lots of hand-holding required. Big companies won’t touch it. That’s precisely where startups thrive.
What Investors Look For: 5 Ways to Validate a Technical Moat
Positioning solves the “who are you” problem. But investors have a second question: “Why you?”
A technical founder’s instinct is to list technical advantages: our model is better, our architecture is superior, our benchmarks are higher. These are necessary but not sufficient. What investors really want to know is: can your technical advantage translate into a durable competitive barrier?
The following five moat dimensions synthesize classical competitive strategy frameworks (Porter’s switching costs, a16z’s data network effects, etc.) with my practical observations in agent infrastructure. They’re not inventions — they’re classifications:
Moat 1: Proprietary Data Loop
Does your system generate proprietary data through usage, and does that data make the system better over time?
How to validate: Show a time-series chart. X-axis is usage duration, Y-axis is some quality metric. If the curve trends upward, you have a data loop. If it’s flat, you have data but no loop.
Key distinction: data loop ≠ having lots of data. Many companies sit on mountains of data with no loop — data growth doesn’t automatically improve product quality. The key to a loop is that feedback is systematically fed back into the model or decision logic. For example, an agent observability tool that automatically funnels user-annotated “this agent behavior was abnormal” data back into its anomaly detection model, with every annotation improving detection accuracy — that’s a data loop.
Moat 2: Systems Complexity
Does your system have enough internal complexity that competitors can’t easily replicate it even after seeing your architecture?
How to validate: Count the number of interdependent components in your system. If it’s 3, a competitor can clone it in a month. If it’s 15, with non-trivial interactions between components, replication time is measured in years.
But be careful: complexity is a double-edged sword. Internal complexity protects you from being copied, but also protects you from iterating on yourself. Good systems complexity is externally complex, internally simple — modular design done well, with each module independently testable and independently deployable.
Moat 3: Switching Cost
How expensive is it for users to migrate to a competitor?
How to validate: Ask existing users a question: “If our product disappeared tomorrow, how long would it take you to reach the same level of effectiveness with an alternative?” If the answer is “a day,” you have no switching cost. If the answer is “three months,” you do.
Agent infrastructure has naturally high switching costs because agent behavior depends on the infrastructure’s specific behavior. Migration isn’t just swapping an API endpoint — it’s re-tuning every agent’s behavior.
Moat 4: Distribution Advantage
Do you have a distribution channel that competitors don’t?
How to validate: How do your users find you? If the answer is “a Hacker News post,” that’s not a distribution advantage — that’s a one-time stroke of luck. A distribution advantage is a repeatable acquisition channel: being embedded in a high-frequency toolchain (like an IDE plugin or CI/CD pipeline), or becoming the de facto standard in a community.
Figma is the textbook case: browser-first → share a link for design review → bottom-up spread within teams → jump from “design tool budget” to “team collaboration platform budget.” When your tool expands beyond the target user group (PMs and engineers using it too), both the budget ceiling and the decision-maker change. A plugin ecosystem is the critical path to platform status — third parties build on your product, and user investment becomes sunk cost.
Another distribution pattern worth studying is Excel: the combination of ease-of-use and flexibility creates a Lindy effect. Two startup paths fork from Excel — build a specific vertical replacement (Carta turned equity management into an end-to-end experience), or inherit its design philosophy for a new category (Figma inherited the “low floor + high ceiling” combination).
Moat 5: Speed of Iteration
All else being equal, do you iterate faster than the competition?
How to validate: Show your release cadence. Shipping a release every week, with each release driven by user feedback — that alone is a moat. Because speed isn’t something you improve by adding headcount (see The Mythical Man-Month); it comes from architectural decisions and how the team works.
If you read Chapter 4, you’ll realize this is exactly the core value of OPC + autonomous operation. A single person + AI pipeline can iterate faster than a 10-person team — not because AI is smarter, but because the pipeline overhead is lower. No standups, no sync meetings, no PR reviews queued and waiting, no merge conflicts. The Chapter 4 case of 14 ticks, 90 minutes from prototype to npm-publishable is itself the best footnote to speed of iteration as a moat.
HeyGen pushed this idea to the extreme. Their experimentation framework has just three rules: hypothesis first (write down what you’re validating before you start), minimal MVP (the smallest verifiable version that can ship in ≤48 hours), signal strength threshold (user behavior data must hit a preset bar to count as validated; otherwise, kill it immediately). The execution unit is a 2-person strike team — one person sets direction, one person builds, zero coordination overhead.
This produces a 5x experimentation compound interest effect: when your competitor runs one A/B test per month, you run five. Even if each experiment has only a 20% success rate, after five experiments you have a 67% chance of finding at least one winning direction. After a year, your product decisions are built on 60 experiments’ worth of data; your competitor has 12. Speed isn’t a linear advantage — it’s a compounding advantage.
You don’t need all five moats. Two to three strong ones are enough. But a tech project with zero moats isn’t worth pursuing, no matter how good the technology is.
A common mistake technical founders make is treating “technical difficulty” as a moat. “We did something very hard” does not equal “others can’t do this thing.” Technical difficulty decays extremely fast in the AI era — last year’s “hard” is this year’s open-source library function call.
A real moat isn’t “what you built” — it’s “what flywheel effect your work set in motion.”
Monetization Timing and Pricing Power
Moats address defensibility, but moats don’t automatically convert to revenue. The next question founders must answer: when do you start charging, and how?
Most technical founders’ instinct is “grow the user base first, figure out monetization later.” This might have worked in the mobile era (with enough users, you’d eventually find a business model), but in AI startups, this strategy has a fatal flaw: AI products have non-zero marginal cost. Every API call burns money. Revenue-less growth that accelerates is death that accelerates.
A counterintuitive data point: conversion rates are higher when users pay at signup than when they hit a paywall mid-workflow.
The logic is simple: when a user first signs up, their patience and willingness to pay are at peak — they just made an active decision to come to your product, and that decision momentum hasn’t faded yet. Present a reasonable pricing plan at that moment, and they’ll likely accept. But let them use it for free for a while, let them get used to free, then pop up a paywall when they’re mid-task — now you’re not facing “a new user willing to try,” you’re facing “an angry user whose workflow just got interrupted.”
Startups need to monetize earlier, designing payment as part of the product experience rather than bolting it on after the fact. A paywall isn’t a scar on your product — it’s part of the product, as natural as prices on a restaurant menu.
Pricing power is another underappreciated topic. When you’ve built a popular tool, the platform can always take your profits by adjusting revenue splits, changing algorithms, or building a competing feature.
Pricing power is fundamentally about irreplaceability. If the platform can replace your product with an algorithm, you have no pricing power. If users face massive migration costs to leave you, you do. There are three paths to pricing power: control the supply chain (you’re the sole provider), control the demand side (user habits and workflow lock-in), or build a non-commodity product (customized services that can’t be standardized away). In AI, the third path is most viable — deep vertical industry know-how is inherently non-commodity.
From Tool to Network: The SaaS Endgame
Among the five moat dimensions, network effects are the most powerful — and the most commonly misapplied concept. Not every “multi-user product” has network effects. Slack has network effects (all your colleagues are on it, so you must be too), but most SaaS tools don’t.
Real network effects must cross enterprise boundaries. Carta’s trajectory illustrates this: started as a single-company cap table tool → gained enough startup adoption that investors started checking their portfolio on it → naturally expanded into Fund Administration → single-enterprise SaaS became a cross-enterprise financial network.
Key insight: network effects aren’t designed — they emerge naturally from sufficient penetration of a single-point tool. Solve one specific problem, achieve enough penetration, then discover that users have a natural need to connect with each other, and build the connection layer on top.
The implication for founders: “forking from Excel” (building a specific vertical) is a smarter play than “replacing Excel” (building a general platform). The Lindy effect tells you — something that’s existed for 40 years is expected to exist for another 40. Frontal assault is almost certain to fail.
Chapter Summary
This chapter zoomed out from individual skills to a market perspective. Five core arguments:
1. AI industry profits follow a smile curve. Upstream infrastructure and downstream vertical applications are high-margin; midstream foundation models are squeezed. If you have neither NVIDIA’s capital barriers nor deep vertical domain expertise, don’t get stuck in the middle.
2. Stronger models, weaker defensibility. Under the triple force of rising capability, collapsing cost, and knowledge spillover, the model itself is not a moat. Real moats are network effects, pricing power, and vertical data flywheels.
3. Narrative matters more than technology — but only if the narrative and technology are consistent. From “Multi-Agent Orchestration Platform” to “Cognitive Resilience Engine,” the core technology didn’t change; the narrative framework did. But narrative isn’t spin — it must be strictly consistent with your architecture philosophy and business model. Incumbents’ margin blind spots give founders a window of opportunity, but you need to seize it in market language, not tech language.
4. A technical moat is a flywheel, not a wall. Proprietary data loop, systems complexity, switching cost, distribution advantage, speed of iteration — the common trait across all five moats is that they strengthen over time rather than erode. Figma’s browser-first PLG strategy is the textbook case for distribution advantage; HeyGen’s 5x experimentation compounding is the extreme expression of speed of iteration.
5. From tool to network, from charging to pricing power. Monetize earlier; design payment as part of the product experience. From single-enterprise SaaS to cross-enterprise network effects (the Carta path), from forking off Excel to deep vertical specialization — the SaaS endgame isn’t a better tool, it’s an irreplaceable node.
For technical founders, the hardest cognitive shift isn’t learning a new technology — it’s learning to describe the value of technology in the language of the market. Technology in search of a market is a comfortable state — you get to keep doing what you love in the world of technology. But startups don’t allow that kind of comfort.
Next chapter, we get into the war stories: lessons distilled from 227 memory cards — the kind of bugs where the surface symptom and root cause are separated by several layers of indirection.