In the previous chapter, we armed an AI team — spawn-vs-delegate decisions, explicit routing, and parallel conflict management. But having a team is just the starting point. A well-equipped team whose every move requires the commander’s sign-off is still bottlenecked by the commander’s attention bandwidth. This chapter addresses the question: how do you let this team run on its own, while you only intervene at critical junctures?
Three Stages: Micro-Management → Macro-Delegation → Autonomous Operation
The way most people use AI to write code looks like this: you write a prompt. Wait for AI to spit out some code. Eyeball it. Tweak the prompt if it’s off. Back and forth, an entire afternoon gone, with output roughly equivalent to what a mid-level programmer could do in an hour.
This is not an AI-native workflow. This is using AI as Stack Overflow.
I went through three stages, each separated by a cognitive threshold.
Stage One: Micro-Management. You watch every step. Write a function, review it. Fix a bug, review it. Add a test, review it. You are the bottleneck; AI is a typewriter. Token efficiency at this stage — meaning the ratio of your review time to AI’s productive work time — is roughly 1:1.
Stage Two: Macro-Delegation. You learn to batch tasks. Not “write me a function,” but “here’s the spec for this module — implement it, including tests and error handling.” You start trusting AI to make autonomous decisions within a larger scope. Token efficiency jumps to 1:5 or even 1:10.
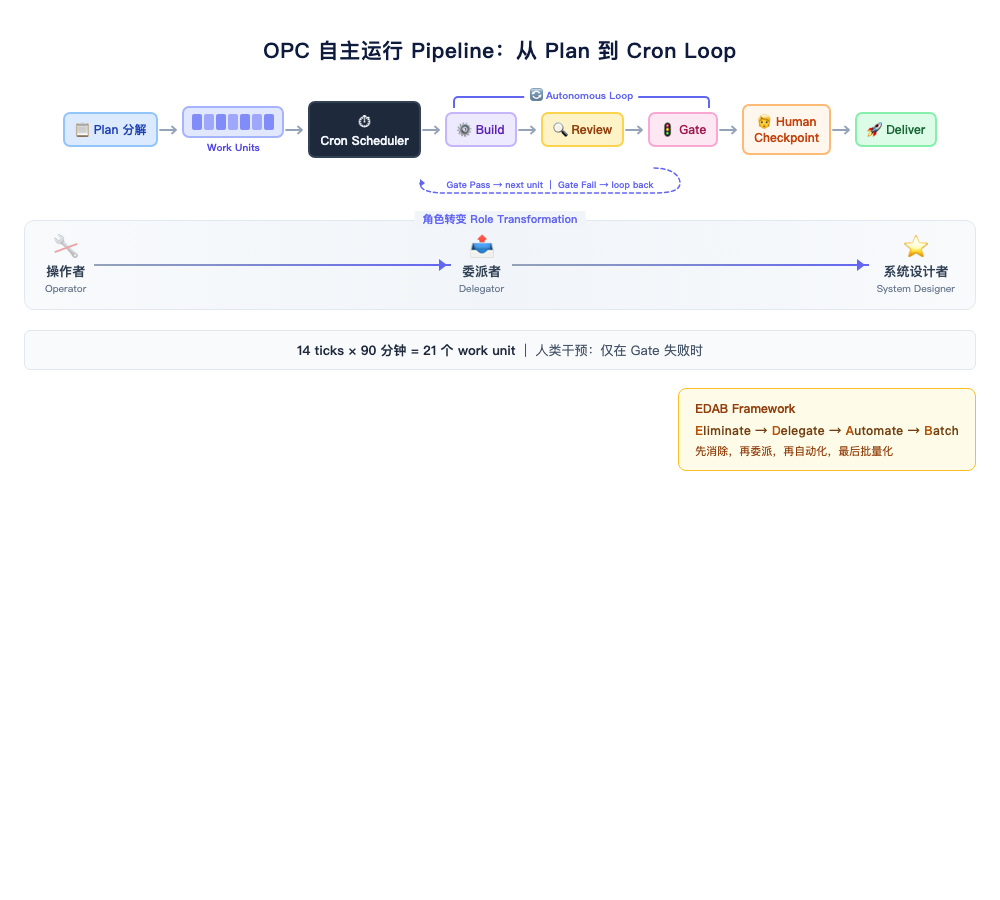
Stage Three: Autonomous Operation. You stop spoon-feeding tasks one by one. You design a pipeline and let AI decompose the plan, execute, verify, and iterate on its own. Your role shifts from operator to architect + reviewer. At this stage, one person can complete 21 work units — each a discrete, shippable change such as a bug fix, a new test, or a config update — in 90 minutes. Not because you type faster, but because you’re no longer in the loop.
These three stages build on each other: first you learn to drive a single AI (the protocol and harness from Chapters 1–2), then you learn to coordinate multiple AIs (the multi-silicon approach from Chapter 3), and only then can you let the whole system run autonomously. Each layer is a prerequisite for the next.
The reason one person can become a team isn’t that AI got smarter — it’s that you learned to get out of the way.
OPC: A One-Person Pipeline
OPC (One-Person Company) isn’t a romantic concept. It’s an engineering problem: how do you turn yourself into a pipeline?
A traditional software team’s pipeline looks roughly like this:
PM writes spec → Engineer implements → QA tests → Tech Lead reviews → DeployFive roles, at least three days. In OPC, this pipeline compresses to:
You write spec → AI implements → AI tests → AI reviews → You make final call → AI deploysOne person, but you’re not doing everyone’s job. You do exactly two things: define the problem and make the final call. Everything in between — implementation, testing, review — is delegated to AI.
Put differently: OPC is fundamentally an architect managing a team of bricklaying robots.
The real shift that coding agents bring isn’t “writing code faster” — it’s a wholesale redefinition of your role. You go from executor to designer. A bricklayer worries about whether each brick is straight; an architect worries about whether the wall should exist at all. Once AI takes over the bricklaying, “programming” doesn’t disappear, but what you need to learn is no longer syntax and APIs — it’s logical decomposition: how to break a fuzzy goal into clear tasks an AI can execute independently.
This means development becomes asynchronous collaboration. You stop hand-writing functions and start giving agents tasks, not problems. “Help me optimize this page’s performance” is a problem — the agent will ask you ten follow-up questions. “Get first-contentful-paint LCP under 2.5 seconds; methods limited to image lazy-loading and critical CSS extraction” is a task — the agent can run it to completion autonomously. The difference is night and day.
In the OPC era, everyone is becoming a CTO. Not because you’ve mastered more tech stacks, but because what you’re doing is structurally identical to what a CTO does: define architecture, allocate resources, make go/no-go decisions. The only difference is your “team” is made of silicon.
I learned this the hard way: there’s a missing layer between plan decomposition and auto-termination. What do I mean? AI can break a large task into subtasks (plan decomposition). AI can also judge whether a single subtask is done (completion check). But AI is bad at judging “whether the whole thing has converged enough to stop.”
This isn’t an intelligence problem — it’s a feedback loop design problem. Once you automate decomposition, execution, and verification, you need an explicit termination condition. Otherwise AI will keep polishing something that’s already good enough, or keep banging its head against a dead end.
My solution is dead simple: give each autonomous loop a tick budget. A tick is one cycle of the loop — AI receives a task, executes, verifies, and reports back. Whatever gets done in 14 ticks is what ships. When the budget’s up, stop. A human reviews the overall result and decides whether to kick off another round.
This gap is real. If you want to do 24-hour autonomous operation, every link in the chain — plan decomposition → execution → verification → convergence check → auto-termination — must be reliable. Current LLMs do fine on the first three, but convergence check still needs a human in the loop — at least as of 2026.
Iterative Review: The Value of the Devil’s Advocate
The mechanics of review were covered in the first two chapters. Here I’ll share one pattern that’s particularly effective in the OPC pipeline: multi-round review amplification.
After the standard correctness review (Round 1) and robustness review (Round 2), add a Devil’s Advocate round (Round 3). Crucially: this Devil’s Advocate must be a separate subagent (spawn a new session), not the same-session persona swap criticized in Chapter 2. The difference matters — an independent session has no anchoring effect from prior context and can genuinely evaluate from an adversarial position. The instruction is simple: “Your job is to kill this design. Find a reason to prove that this approach is fundamentally wrong.” Each round’s prompt includes findings from all previous rounds — perspectives accumulate.
Most of the time, Round 3 doesn’t find a fatal issue — which actually validates the first two rounds. But once, Round 3 genuinely killed a design. That design had passed both correctness and robustness reviews because it was technically correct and handled edge cases well. But the devil’s advocate perspective uncovered a fundamental problem: this design was solving a problem that shouldn’t exist. Adjusting the upstream data model slightly made the entire module unnecessary.
Without Round 3, that design would have been implemented, tested, deployed, and ripped out in a refactor three months later.
Three rounds cost roughly 3–4x the tokens of a single round, but the defects caught by stacking perspectives scale nonlinearly. This method also applies to non-code content — docs, pitch decks, blog posts. Have AI review the same piece from different personas, and cross-signals (issues flagged by multiple personas simultaneously) are the highest priority.
Cron Loop: Automated Product Iteration
Iterative review solves the quality problem. But OPC has a bigger challenge: iteration speed.
A traditional team’s iteration cadence is measured in weeks. Monday planning, Friday demo, five days of coding in between. One iteration per week. If you’re a solo operator working at that pace, you’ll never catch a five-person team.
My solution is the cron loop: turn product iteration into an automated cycle, one cycle every 30 minutes.
But before getting into the specifics, there’s a more fundamental question: each cron loop round surfaces a pile of issues — how do you decide which ones to act on and which to skip?
The answer is the EDAB framework — Eliminate → Delegate → Automate → Batch. Note the order: it’s a funnel, with each step reducing the input volume for the next.
E (Eliminate): The first step isn’t optimizing execution — it’s questioning existence. Does this task actually need to be done? If a minor upstream design change would prevent this bug from ever occurring, the right move is to fix upstream, not patch the symptom. Skipping E and jumping straight to A (Automate) means you’re efficiently doing work that shouldn’t be done at all.
D (Delegate): Whatever can’t be eliminated — can AI handle it autonomously? Most issues surfaced in a cron loop — UI fixes, test backfills, documentation updates — are natural delegation targets.
A (Automate): Things that require human involvement but can be templatized — turn them into scripts or prompt templates that execute automatically next time.
B (Batch): Whatever genuinely requires human judgment, accumulate and process in batches to minimize context switching.
In OPC, you face a massive volume of decisions daily. EDAB is the priority pruning tool. Without this funnel, your cron loop becomes a conveyor belt with no filter — processing everything and accomplishing less.
A single cycle is EDAB instantiated:
Walk through current state → Identify issues → EDAB pruning → Parallel execution (AI does the work) → Verify → Converge30 minutes. No more, no less. If an issue can’t be resolved in 30 minutes, it gets broken down into smaller issues for the next cycle.
The key design decision in this loop is parallel execution. Within a single cycle, AI doesn’t fix problems sequentially — it tackles multiple independent changes simultaneously. Technically this is trivial — spin up multiple sessions. But cognitively it requires a shift: you stop reviewing each individual change and instead review the delta in overall state.
A real data point: 5 cron loop cycles, 150 minutes total, took a product from “barely functional” to “ready to show users.” Those 5 iterations covered UI fixes, API refactoring, error handling, documentation updates, and performance optimization.
But here’s an important observation: diminishing returns in later rounds are normal.
The first two cron loop cycles produce the most output because the low-hanging fruit is most plentiful. By the third round, marginal improvement per cycle drops noticeably. By the fifth, you’re mostly fixing polish-level issues.
This isn’t the system breaking down — it’s the natural law of diminishing returns. The right move isn’t to keep running a sixth round, a seventh round, but to stop and redefine the problem. Maybe the product doesn’t need more polish; it needs a new feature. Maybe the UI is good enough and the bottleneck is the onboarding flow.
The cron loop gives you speed. But speed itself isn’t the goal. Knowing when to stop matters more than going fast.
So how far can you push it before things break?
Honest Capability Boundaries: What Still Can’t Be Done
I’ve seen too many AI evangelists claiming “AI can replace an entire engineering team” or “one person equals ten.” These statements are true under specific conditions, but if you actually believe them wholesale, you’ll get burned where it hurts most.
Let me give you an honest data point.
I ran a 24-hour autonomous operation boundary test. Not demo-grade — real product, real codebase, real complexity. The result: 5 reviewers (different roles, different perspectives) found 14 bugs in the 24-hour autonomous output. Sample size is a single experiment — not statistically significant — but the directional conclusion is clear.
Fourteen bugs. Not typos — bugs that would affect users. Including:
- Logic errors: inverted conditionals causing incorrect behavior in edge cases
- Integration issues: two independently implemented modules with inconsistent interface assumptions
- Omissions: functionality explicitly required in the spec but skipped in implementation
- Regressions: fixing one bug while introducing another
These aren’t caused by AI “not being smart enough.” These are systemic problems that emerge whenever autonomous operation runs long enough. The causes are clear:
- Context drift (not to be confused with concept drift in ML). As the conversation gets longer, AI’s recall of earlier decisions degrades. It doesn’t forget — the context is still there — but its attention skews toward recent content.
- Error compounding. In supervised mode, a human catches small errors at every step. In autonomous mode, a small error propagates to subsequent steps and gets treated as a correct premise for further work.
- Specification gap. Even the best spec has gaps. In supervised mode, a human fills them with common sense. In autonomous mode, AI either guesses (often wrong) or skips them (leaving landmines).
These data points tell me several things:
First, the time scale for autonomous operation is currently measured in hours, not days. 21 work units in 90 minutes with controllable quality. 24 hours unsupervised with uncontrollable quality. This boundary hasn’t been broken in 2026.
Second, the number and diversity of reviewers matters more than AI capability itself. 5 reviewers found 14 bugs not because each reviewer was exceptional, but because they looked from different angles. Cross-detection outperforms deep review from a single perspective by a wide margin.
Third, don’t run an eval loop before fixing the root cause. This lesson cost me real money. Once, I discovered a systematic issue in AI-generated code — not a one-off bug, but a pattern caused by a flaw in prompt design. My choice at the time: run a full eval loop first, quantify the severity of the problem, then fix it.
Result: 23M tokens, roughly $162,1 all wasted.
Because every round of the eval loop was evaluating a system with a known defect. The eval only confirmed what I already knew. The right approach is fix the root cause first, then run the eval. This sounds like common sense, but when you’re caught in the momentum of autonomous operation, “just let the system keep running and deal with it later” is an incredibly seductive trap.
$162 isn’t much. But it taught me a principle: autonomous does not mean unattended. You can let AI run on its own, but you can’t stop watching the direction.
In Practice: From 10-Check Spike to npm-Publishable in 14 Ticks
Let me walk through a complete real-world case.
The task: take an internal CLI tool from “it runs” to “it ships on npm.” Specifically, go from a prototype failing 10 checks to a package with sufficient test coverage, complete documentation, green CI, and a clean npm publish.
I ran this using the OPC loop protocol. 14 ticks, 90 minutes, 21 work units completed.
Tick-by-tick record:
Ticks 1–3: Infrastructure. Fix CI pipeline, fill in tsconfig, configure ESLint. This is AI’s sweet spot — pattern-based, rules are explicit, no creative judgment needed. 3 ticks, 6 work units.
Ticks 4–7: Core bug fixes. 4 of the 10 failing checks were logic errors. AI fixed them one by one, running the full test suite after each fix to confirm no regression. 4 ticks, 5 work units.
Ticks 8–10: Test backfill. The original prototype had roughly 30% test coverage. These three ticks brought it to 85%. AI writes tests extremely efficiently because it can derive the cases to cover directly from the implementation code. 3 ticks, 5 work units.
Ticks 11–13: Documentation and packaging. README, CHANGELOG, package.json metadata, npm publish prepublish script. 3 ticks, 4 work units.
Tick 14: Final verification. Run the full CI pipeline, confirm all checks pass. Run npm publish --dry-run, confirm package structure is correct. 1 tick, 1 work unit.
A few observations:
Work unit distribution is uneven. The first 3 ticks completed 6 units (average 2.0), the middle 7 ticks completed 10 units (average 1.4), the last 4 ticks completed 5 units (average 1.25). The diminishing returns curve is clearly visible.
Tick duration is uneven. Infrastructure ticks were about 4–5 minutes each (fast AI execution, simple decisions). Core bug fix ticks were about 7–8 minutes each (requires understanding context, may need multiple attempts). The final verification tick was the longest, around 10 minutes (waiting for CI to finish).
Were 14 ticks enough? For a task of this scale, yes. But for something bigger — say, building a complete SaaS from scratch — 14 ticks would only get you through scaffolding. Testing 24-hour autonomous operation requires a much larger task. This is why I say the current capability boundary is “hours” not “days.”
The significance of this case isn’t “shipped an npm package in 90 minutes.” It’s this: throughout the entire process, I didn’t write a single line of code. I wrote the spec. I made prioritization decisions between ticks. I did the final verification. But implementation, testing, bug fixes, documentation — all done by AI.
That’s what autonomous operation means. It’s not AI running by itself. It’s you designing a system in which AI runs by itself.
The Shadow of Efficiency: When Agents Kill Friction
At this point, I need to honestly confront an uncomfortable question.
This entire chapter has been about efficiency — the speed of cron loops, the throughput of parallel execution, the pruning power of EDAB. But humanity’s greatest creations almost never came from efficient pipelines. They came from detours, resistance, and friction.
Da Vinci spent three years painting The Last Supper, much of it “wasted” — staring at walls, arguing with the monastery’s prior, running off to study optics. Give Da Vinci a cron loop with 30-minute cycles, and he might have finished a painting faster — but that painting wouldn’t have been The Last Supper.
The way AI improves efficiency is, at its core, by eliminating friction. But creativity needs friction as fuel. When you manually debug a bug for two hours, your understanding of the system reaches a depth that AI’s instant fix can never provide. When you argue with a colleague about an architecture decision for half a day, the final solution is far better than what either person would have reached alone.
In OPC mode, you no longer argue with people, no longer debug by hand, no longer get forced to solve problems creatively within tight constraints. Everything gets optimized away. Efficiency goes up, but something is lost.
The deepest challenge facing AI-native organizations isn’t technical — it’s philosophical: when agents absorb all execution-level friction, humans must deliberately manufacture new friction.
How? A few practices:
- Intentionally skip AI for certain tasks. Set aside dedicated time each week to hand-write code, hand-draw architecture diagrams. Not because it’s more efficient — precisely because the “inefficiency” of manual work is where deep thinking happens.
- Use the Devil’s Advocate not to find bugs, but to create conflict. The Round 3 review described earlier has value beyond catching technical defects — it forces you to re-examine your own assumptions from the opposing side.
- Periodically “degrade.” Turn off the autonomous loop, drop back to micro-management mode, and walk through a complete workflow by hand. You’ll discover new insights because you’re re-engaging with details that automation had hidden from view.
This isn’t nostalgia or anti-technology. It’s an engineered cognitive strategy: among the friction that AI optimizes away, distinguish what is pure waste (eliminate it) from what is fuel for creativity (preserve it, or even amplify it).
The tension between efficiency and creativity is a permanent feature of autonomous operation. Don’t pretend it doesn’t exist.
Chapter Summary
This chapter’s core argument compresses to three statements:
1. Autonomous operation is an engineering problem, not an intelligence problem. The OPC loop’s tick budget, the cron loop’s fixed cycles, iterative review’s stacked perspectives — these are all designable, tunable, reproducible pipelines. AI doesn’t need to be “smarter” to run autonomously; you need better system design.
2. The leverage points for amplification are parallelism and structure, not speed. One person completing 21 work units in 90 minutes isn’t because AI types fast — it’s because parallel execution eliminates serial waiting, and structured review perspectives replace redundant single-point inspection. Speed is the result, not the cause.
3. Boundary awareness is the most important capability in autonomous operation. Hours are controllable; days are not. Knowing when to stop matters more than going fast — whether it’s the diminishing returns of the cron loop or the sunk cost of a $162 eval loop. Autonomous does not mean unattended.
Next chapter, we zoom out from the individual to the market. If autonomous operation is a personal force multiplier, where are the startup opportunities in the agent era? Spoiler: not where you think.
Footnotes
-
Based on LLM pricing at the time; actual costs vary by model and provider. ↩