Agent 时代不是去掉 GUI
第四章讲了一个人如何把自己变成一条 pipeline——OPC、cron loop、iterative review,这些是个人层面的能力放大器。但 pipeline 造出来了,该造什么产品?瞄准什么市场?
这一章把视角从个人拉到产业。即使你不打算创业或融资,这章的框架对技术选型和职业方向选择同样关键。 你不需要成为创业者才需要理解 infrastructure 与 application 的分层逻辑——选择加入哪家公司、押注哪个技术栈、用什么架构做 side project,背后都是同一套判断框架。如果你对商业分析不感兴趣,可以直接跳到第六章的工程手札——那里是纯粹的踩坑记录。
每隔几年,技术圈就会集体犯一次同样的错误:把 “新范式” 简单理解为 “去掉旧范式的某个部分”。
移动互联网来了,有人说 “就是把网页缩小到手机屏幕上”。云计算来了,有人说 “就是把服务器搬到别人家”。现在 agent 时代来了,最流行的叙事是:“去掉 GUI,让 AI 直接操作。”
这是错的。不是小错,是方向性的错误。
去掉 GUI 是一个 UI 层面的改动。它假设问题出在 “人类需要手动点按钮”,而 agent 的价值是 “AI 替人点按钮”。如果你按这个思路做产品,你会做出一个传统的、基于屏幕坐标的 RPA(Robotic Process Automation)——一个脆弱的、在底层 UI 一改就崩的自动化脚本。
Agent-native 的正确思路是重新发明交互模型,而不是去掉交互模型。
三个设计原则:
Plugin > Standalone。 Agent 不需要一个独立的应用。Agent 需要的是 可以被调用的能力。如果你在做一个 agent 时代的产品,首先问自己:它能不能被 agent 当作一个 tool 来调用?如果不能,你的架构就是错的。MCP(Model Context Protocol)的爆发不是偶然的——它为 tool 和 resource 的暴露提供了标准化协议,让 “应用” 可以作为 “能力” 被 agent 发现和调用,这才是 agent-native 的正确抽象。
Specific > Platform。 “做一个 agent 平台,让所有 agent 都能在上面跑” 听起来很性感,但这是一个典型的 “技术人思维”。真正赚钱的不是平台,是平台上解决具体问题的 specific tool。你不需要做 “agent 的操作系统”,你需要做 “agent 在做代码 review 时用的那个 specific 工具”。
Observability > Auto-fix。 大多数团队在追求 “让 agent 自动修复问题”。但真正的需求是 “让人类看懂 agent 在做什么”。当 agent 操作链条变长——十步、二十步、上百步——可观测性(observability)比自动修复更重要。因为在你信任 auto-fix 之前,你首先需要理解 agent 的行为。没有 observability 的 auto-fix 是一个黑盒,而黑盒是 production 环境的噩梦。
这三个原则指向同一个结论:agent 时代的机会在 infrastructure layer,不在 application layer。
Infrastructure Layer > Application Layer
为什么是 infrastructure 而不是 application?
让我用一个类比。移动互联网早期,最终赚到大钱的公司不是做 app 的(虽然有些 app 确实赚了钱),而是做 infrastructure 的:Stripe 让 app 能收钱,Twilio 让 app 能发短信,AWS 让 app 能部署。App 来来去去,infrastructure 越用越深。
Agent 时代的格局高度类似:
-
Application layer: 做一个 “AI 帮你写邮件” 的 app,做一个 “AI 帮你订机票” 的 agent。这些产品的问题是 护城河极浅。任何一个 LLM provider 都可以在下一个版本里把你的功能变成内置能力。你的产品就是 LLM 的一层 prompt wrapper。
-
Infrastructure layer: 做 agent 的 memory 系统,做 agent 的 tool 注册和发现协议,做 agent 操作的 observability 平台,做 multi-agent 之间的通信和协调层。这些产品的护城河是 系统性的复杂度——不是随便一个 prompt 就能替代的。
一个简单的判断标准:如果下一代 frontier model 发布的那天你的产品会过时,那你就在 application layer。如果那天你的产品反而更有用了,你就在 infrastructure layer。
LLM 越强,需要的 infrastructure 越多——更多的 memory,更复杂的 tool 集成,更精细的 observability,更可靠的 orchestration。这就是 infrastructure layer 的结构性优势。
但 “infrastructure vs application” 的二分法过于粗糙。要看清机会在哪里,需要更精细的地图。
AI 产业价值链:微笑曲线
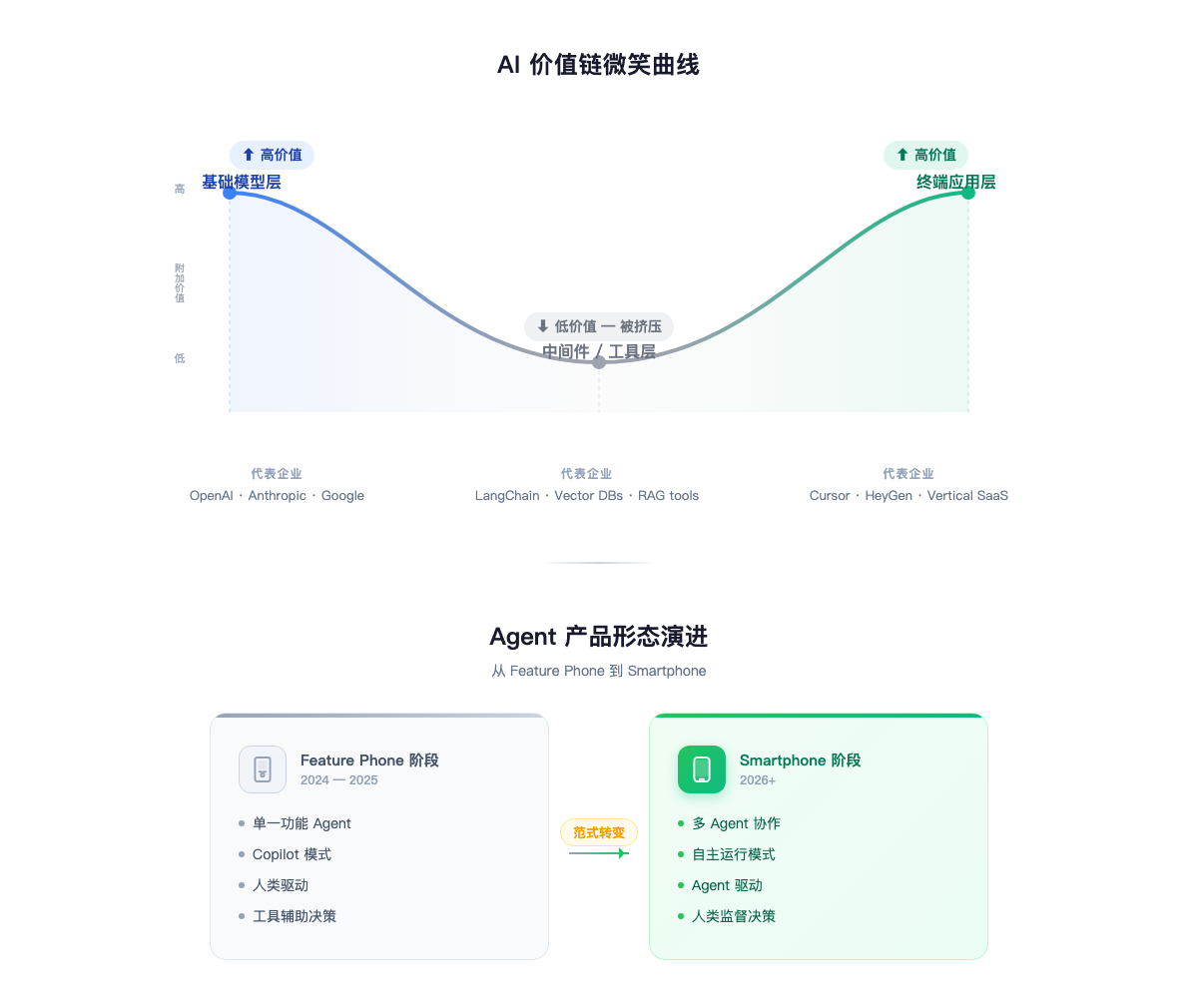
如果你画一条 AI 产业的利润曲线,它的形状很像微笑——两头高,中间低。
上游:基础设施。 GPU、云计算、训练集群。NVIDIA 的毛利率超过 70%,云厂商靠 AI 算力需求赚得盆满钵满。这是资本密集型的游戏,壁垒是规模和物理世界的稀缺性。
中游:通用模型。 GPT、Claude、Gemini、DeepSeek。技术含量最高,但利润率被挤压得最厉害。原因很简单:模型能力趋同的速度远超预期,而开源社区(特别是 DeepSeek 的蒸馏路线)在不断拉低获取先进模型能力的成本。通用模型层的竞争正在变成一场消耗战——谁都很强,谁都不赚钱。
下游:垂直应用。 这里是利润回升的地方。据报道,Cursor 在约两年内突破 ARR $100M,且增速仍在加速。它不是在做”通用 AI IDE”,它在做”开发者的 AI 工作流”——一个深度嵌入垂直场景的产品。垂直应用的价值不在模型本身,在于对用户工作流的理解深度和产品化能力。
微笑曲线告诉你一件事:如果你既没有 NVIDIA 的资本壁垒,也没有垂直场景的深度理解,卡在中间做通用模型层的工具,你会被两头挤压。 要么往上走做 infrastructure(但需要巨大资本),要么往下走做垂直应用(需要对场景的深度 know-how),中间地带是最不舒服的位置。
这也修正了前面 “infrastructure > application” 的说法——更准确的表述是:深度垂直的 application 和底层 infrastructure 都有价值,没价值的是浅层的通用 application。
产品形态演进:Feature Phone vs Smartphone
如果微笑曲线告诉你”在哪里打”,那产品形态则决定”用什么武器打”。
当前 AI 产品有两种基本形态,我借用手机行业的类比来区分:
Feature Phone 模式: 在现有产品上集成 AI 能力。Monica 集成各家模型 API 做聚合助手,Notion 加了 AI 写作功能,Gmail 加了 AI 摘要。核心逻辑是在旧框架里加入 AI 模块——用户体验没有根本改变,只是某些步骤变快了。
Smartphone 模式: 让 AI 成为产品的核心交互范式。Cursor 不是”VS Code 加了个 AI 插件”,它重新定义了开发者和代码的交互方式——AI 在 loop 里,不是在侧栏里。Manus 让 AI agent 自主执行多步骤任务,用户给目标,agent 自己找路径。核心逻辑是围绕 AI 能力重新设计整个产品。
这个类比有局限——Feature Phone 和 Smartphone 在手机行业是替代关系,但在 AI 产品领域,两种模式可能长期共存。原因很简单:不是所有场景都需要 Smartphone 模式。给 Excel 加个 AI 公式助手(Feature Phone)和做一个 AI-native 数据分析工具(Smartphone)解决的是不同层次的问题,服务的是不同阶段的用户。
更深层的演进正在发生:从 App Store 到 Agent Marketplace。
传统应用市场是标准化的——每个 app 提供固定功能,人类通过 GUI 交互。Agent marketplace 的逻辑完全不同:
- 从标准化到定制化。 Agent 能力可以按需组合,不再是”下载一个 app 获得全部功能”。
- 从人机界面到机器界面。 Agent 发现和调用另一个 agent 的能力,不需要 GUI,需要的是标准化的 API 和协议(这就是 MCP 的价值)。
- 从持久安装到临时调用。 你不”安装”一个 agent,你在需要时调用它的能力,用完即走。
但 Agent marketplace 要真正运转,需要解决四个核心问题:连接(agent 怎么发现其他 agent 的能力?)、激励(能力提供者怎么获得回报?)、信任(怎么确保被调用的 agent 不会搞砸?)、冷启动(marketplace 两边都没人时怎么启动飞轮?)。这四个问题,每一个都是创业机会。
防御性悖论:模型越强,壁垒越弱
在产业格局中,有一个反直觉的现象值得单独讨论:AI 模型的防御性和它的能力成反比。
传统软件的逻辑是:产品越好 → 用户越多 → 数据越多 → 产品更好。这是一个正反馈循环,壁垒随时间增强。
AI 模型的逻辑不同。三个力量在同时作用:
- 能力上升。 每一代模型都在变强。但这也意味着”做出一个够用的模型”的门槛在降低,而不是升高。
- 成本暴跌。 GPT-4 级别的能力,两年前需要 $60/M tokens,现在开源模型几乎免费。成本降低意味着进入门槛降低。
- 外部性扩散。 DeepSeek 证明了一件事:你花几十亿美金训出来的模型能力,别人可以通过蒸馏以百分之一的成本获取大部分价值。你的投入产生的知识溢出到了整个生态。
这三个趋势加在一起的结论是:模型本身不是壁垒。 今天你的模型领先六个月,六个月后这个优势就被抹平了。
那壁垒在哪里?在模型之外的东西:
- 网络效应。 用户越多 → 使用数据越多 → 产品体验越好 → 用户更多。这和模型能力无关,和产品生态有关。
- 定价权。 当你深度嵌入用户的工作流,用户对价格变得不敏感。Cursor 从免费到 $20/月 Pro 再到 $200/月 Ultra,付费用户有增无减——因为它已经成为开发者每天的操作系统,切换成本极高。
- 垂直场景的数据飞轮。 通用模型的数据优势容易被追平,但特定垂直场景(医疗诊断、法律合同、芯片设计)的高质量标注数据极难获取,这才是真正的壁垒。
对创业者来说,这意味着一个战略选择:不要赌你能训出最好的模型,要赌你能建出最深的护城河。 模型是地基,但地基可以换——护城河不能。
但说 “做 infrastructure” 太抽象了。具体应该做什么?以及更重要的——怎么判断一个 infrastructure 的 idea 值不值得投入?
“Technology in Search of a Market” 的诊断框架
技术创始人最常见的失败模式不是技术不行,而是 technology in search of a market——手里有一把锤子,满世界找钉子。
我见过太多这样的项目:技术 demo 非常惊艳,GitHub star 蹭蹭涨,但问到商业化就含糊其辞。“先把技术做好,市场自然会来。” 不,市场不会自己来。市场只会去找能解决它问题的人,不管那个解决方案是用 AI 做的还是用 Excel 做的。
诊断一个技术项目是否值得投入(不管是投入时间还是投入资金),我用三个问题:
FOR WHOM?
你的用户是谁?不是 “开发者”——太宽泛了。是 “正在把 monolith 拆成 microservices 的 30-100 人 backend 团队”,还是 “第一次部署 LLM 到 production 的 Series A 创业公司”?
用户越具体,你的产品决策越清晰。如果你不能用一句话描述你的用户是谁、他们此刻的头号痛点是什么,你还没准备好开始。
WHY NOW?
为什么这个问题今天可以被解决,而去年不行?这个问题过滤掉了大量 “好主意但时机不对” 的项目。
Agent 时代的 WHY NOW 通常是这些:
- LLM 的 context window 从 4K 到 128K(部分模型号称支持 1M,但实际长 context 尾部质量仍有衰减),使得某些之前不可行的交互模式变得可行
- Tool use / function calling 从 hack 变成了原生能力
- MCP 等协议的出现让 agent-tool 集成有了标准化的基础
- 企业客户从 “试试看 AI” 进入 “必须部署 AI” 的阶段
如果你的 WHY NOW 是 “AI 很火”,那不是 WHY NOW,那是 FOMO。
HOW BIG?
市场有多大?这不是让你编一个 TAM/SAM/SOM(Total Addressable Market / Serviceable Addressable Market / Serviceable Obtainable Market,即总体市场、可服务市场、可获取市场)的数字。这是问你:如果你的产品成功了,它的天花板在哪里?
一个 agent observability 工具,如果每个运行 agent 的公司都需要,那它的天花板就是 “所有使用 agent 的公司的 infrastructure 预算”。一个 “AI 帮你写邮件” 的 app,天花板就是用户愿意为省五分钟付多少钱——通常不多。
技术好 ≠ 值得投资。 技术好 + FOR WHOM 清晰 + WHY NOW 成立 + HOW BIG 足够大 = 值得投资。四个条件缺一不可。
从 v1 到 v3 的定位演进:一个真实案例
一个朋友的创业项目经历了三次定位迭代,我全程近距离观察并参与了讨论。同一个项目、同一套底层技术,三次定位,三种命运。用它来说明上面的理论是如何在实战中运作的。
v1:“Multi-Agent Orchestration Platform”
第一版定位:做一个多 agent 的编排平台。让不同的 AI agent 能协同工作,像一个团队一样完成复杂任务。
这个定位的问题:
- 太宽泛。 “Multi-Agent Orchestration” 是一个 category,不是一个 product。投资人听到这个会问:“那 LangChain 呢?CrewAI 呢?AutoGen 呢?” 你立刻被拉进了一个红海。
- Technology in search of a market。 “多 agent 协作” 是一个技术能力,但谁需要它?什么场景下,单个 agent 不够用,需要多个 agent 协作?这个 FOR WHOM 没有回答清楚。
- Architecture 哲学和 business model 的矛盾。 如果你要做 “平台”,你的商业逻辑应该是 network effect——越多人用,平台越有价值。但 multi-agent orchestration 的价值不来自 network effect,它来自 orchestration 的质量。这是一个 tool 的逻辑,不是 platform 的逻辑。
第一次被投资人问住的感觉——朋友后来跟我描述——很清晰:对方只问了一句”你的前三个付费客户会是谁”,他发现自己答不出来。技术讲得再好,这一个问题就暴露了根基不牢。
v2:“Agentic OS”
吸取了 v1 的教训,第二版定位提升了抽象层次:做 agent 的操作系统。不只是编排,而是提供 agent 运行所需的一切——memory、tool 管理、权限控制、lifecycle 管理。
这个定位比 v1 好,但有一个致命问题:
OS story 要求 lock-in,但 Unix values 要求 modularity。 如果你说自己是 “操作系统”,投资人期待的是 Windows/iOS 那样的生态锁定——开发者在你的平台上构建,用户在你的平台上使用,切换成本极高。但如果你的技术哲学是 Unix-style 的模块化和可组合性——每个组件独立、可替换、通过标准协议通信——这和 “OS lock-in” 是根本矛盾的。
你不能既说 “我是操作系统,所有 agent 都应该跑在我上面”,又说 “我信仰 Unix 哲学,每个组件都可以替换”。这两句话不能出现在同一个 pitch deck 里。
这就是 positioning-architecture-business contradiction:你的定位、你的架构哲学、你的商业模式,三者必须自洽。任何两者之间的矛盾都会在投资人的追问下暴露。
v3:“Cognitive Resilience Engine”
第三版定位做了一个根本性的转变:不再定义自己是一个 category(platform / OS),而是定义自己解决的是一个 specific problem。
Cognitive Resilience——认知韧性。当 agent 遇到意外情况、模糊指令、conflicting 信息时,它不崩溃、不幻觉、不死循环,而是优雅降级、寻求澄清、或者退回到安全状态。这个概念当时行业里还没有标准术语——但它精确地描述了 production agent 面临的核心挑战。
这个定位的优势:
- FOR WHOM 非常清楚。 任何在 production 环境里跑 agent 的公司。不是玩 demo 的公司,是真的把 agent 用在赚钱的业务上的公司。这些公司最怕的就是 agent 在关键时刻崩掉。
- WHY NOW 成立。 2026 年,越来越多的公司开始把 agent 从 prototype 推向 production。prototype 阶段不需要 resilience——崩了重来就行。production 阶段,resilience 是刚需。
- HOW BIG 够大。 每一个 production agent 都需要 resilience。这不是一个 niche market,这是 agent infrastructure 的核心层。
- Architecture 和 business model 自洽。 Resilience engine 本质上是一个 middleware——嵌入到别人的 agent pipeline 里。这是一个 plugin 逻辑(plugin > standalone),不需要 platform-level 的 lock-in。商业模式是按 API 调用计费或者按 agent 数量订阅。简单、直接、可预测。
从 v1 到 v3,核心变化不是技术变了(底层能力一直是那些),而是 叙事变了。v1 在说 “我有什么技术”,v2 在说 “我是什么品类”,v3 在说 “我解决什么问题”。只有 v3 是投资人愿意听的语言。
这个过程中还有一个更隐蔽的坑:document type mismatch——用错了文档类型回答问题。v1 的 pitch deck 通篇在讲技术实现,但投资人问的不是”系统怎么工作”,而是”谁会买”。措辞怎么改都是错的——因为文档类型本身就是错的。AI 擅长在一个文档类型内部优化(让你的技术描述更精练),但不擅长诊断”你写的根本不是 pitch deck,你写的是技术文档”。这是需要人类判断的地方。
顺便说一句,v1 的失败有一个更深层的原因:在位者的利润率盲区。
Google 比 Amazon 有更好的技术做云计算——但 Google Cloud 在云市场长期排第三。为什么?因为 Google 的核心业务是广告,毛利率 50%+。云计算的毛利率只有 20-30%。当你习惯了高毛利业务,低毛利机会在组织内部拿不到资源和注意力。Amazon 的零售业务毛利率本来就低,所以 AWS 的利润率对 Amazon 来说是”真香”,对 Google 来说是”何必呢”。
这对创业者的启示是:在位者的盲区不是技术盲区,是利润率盲区。 如果你瞄准的市场对在位者来说”利润率太低不值得做”,你天然就有一个窗口期。Agent infrastructure 的早期市场就有这个特征——单价低、客户分散、需要大量 hand-holding,大厂不愿意做。这恰恰是创业公司的机会。
投资人看什么:5 个技术 moat 的验证方法
定位解决了 “你是谁” 的问题。但投资人还有第二个问题:“为什么是你?”
技术创始人的本能回答是罗列技术优势:我们的模型更好、我们的架构更优、我们的 benchmark 更高。这些都是必要的,但不充分。投资人真正想知道的是:你的技术优势是否能转化为持久的竞争壁垒?
以下五个 moat 维度综合了经典竞争战略框架(Porter 的 switching cost、a16z 的 data network effect 等)和我在 agent infrastructure 领域的实践观察。它们不是发明,是分类:
Moat 1:Proprietary Data Loop
你的系统在使用过程中是否产生独有的数据,这些数据是否能让系统越来越好?
验证方法: 展示一个时间序列图。X 轴是使用时间,Y 轴是某个质量指标。如果曲线是上升的,你有 data loop。如果是平的,你只有 data,没有 loop。
关键区分:data loop ≠ 有很多数据。很多公司有大量数据但没有 loop——数据的增长不会自动提升产品质量。Loop 的关键是 feedback 被系统地回馈到模型或决策逻辑中。比如一个 agent observability 工具,如果它把用户标注的 “这次 agent 行为异常” 的数据自动回流到异常检测模型,每一次标注都在提升检测精度——这就是 data loop。
Moat 2:Systems Complexity
你的系统是否有足够的内部复杂度,使得竞争对手即使看到你的架构也无法轻易复制?
验证方法: 数你的系统有多少个相互依赖的组件。如果是 3 个,竞争对手一个月能抄完。如果是 15 个、且组件之间有非平凡的交互,复制周期以年计。
但要注意:复杂度是双刃剑。内部复杂度保护你不被抄,但也保护你不被自己迭代。好的 systems complexity 是对外复杂、对内简单——模块化做得好,每个模块独立可测、独立可部署。
Moat 3:Switching Cost
用户迁移到竞争对手的成本有多高?
验证方法: 问现有用户一个问题——“如果明天我们的产品消失了,你需要多久才能在替代方案上恢复到同样的效果?” 如果答案是 “一天”,你没有 switching cost。如果答案是 “三个月”,你有。
Agent infrastructure 的 switching cost 天然较高,因为 agent 的行为依赖于 infrastructure 的 specific behavior。迁移不只是换一个 API endpoint,而是重新 tune 所有 agent 的行为。
Moat 4:Distribution Advantage
你是否有竞争对手不具备的分发渠道?
验证方法: 你的用户是怎么找到你的?如果答案是 “Hacker News 上的一篇帖子”,那不是 distribution advantage,那是一次性的运气。Distribution advantage 是 可重复的获客渠道:嵌入在某个高频使用的工具链里(比如 IDE plugin、CI/CD pipeline),或者成为某个社区的事实标准。
Figma 是这个 moat 的教科书案例:浏览器优先 → 一个链接就能看评审 → bottom-up 在团队内扩散 → 从”设计工具预算”跳到”团队协作平台预算”。当你的工具扩展到目标用户群之外(PM 和工程师也在用),预算天花板和决策者都变了。Plugin 生态是走向 platform 的关键路径——第三方在你的产品上构建工具,用户投入就沉淀了。
另一个值得研究的 distribution pattern 来自 Excel:易用性和灵活性的结合产生了林迪效应。从 Excel 中分化出的创业路径有两条——做 specific vertical 替代(Carta 把股权管理做成一站式体验),或继承其设计哲学做新品类(Figma 继承了”低门槛+高上限”的组合)。
Moat 5:Speed of Iteration
在所有其他条件相同的情况下,你的迭代速度是否比竞争对手快?
验证方法: 展示你的 release cadence。每周发一个版本、每个版本包含用户反馈驱动的改进——这本身就是一个 moat。因为速度不是靠加人就能提升的(参见《人月神话》),它来自于 architecture 的决策和团队的工作方式。
如果你读了第四章,你会意识到这正是 OPC + autonomous operation 的核心价值。一个人 + AI pipeline 的迭代速度可以超过一个 10 人团队——不是因为 AI 更聪明,而是因为 pipeline 的 overhead 更低。没有 standup、没有 sync meeting、没有 PR review 排队等候、没有 merge conflict。第四章里那个 14 ticks、90 分钟从 prototype 到 npm-publishable 的案例,本身就是 speed of iteration 这个 moat 的最好注脚。
HeyGen 把这个思路推到了极致。他们的实验框架只有三条规则:假设先行(先写清楚要验证什么)、极简 MVP(≤48 小时能跑的最小验证版本)、信号强度阈值(用户行为数据达到预设标准才算验证通过,否则立刻停)。执行单元是 2 人作战小组——一个人定方向,一个人做实现,没有多余的协调成本。
这产生了一个 5 倍速的实验复利效应:当竞争对手一个月做一次 A/B test 时,你一个月做五次。即使每次实验的成功率只有 20%,五次实验之后你有 67% 的概率找到至少一个有效方向。一年之后,你的产品决策是建立在 60 次实验数据上的,竞争对手只有 12 次。速度不是线性优势,是复利优势。
这五个 moat 不需要全部具备。有两到三个强 moat 就足够了。但 零个 moat 的技术项目不值得投入,不管技术本身有多好。
技术创始人容易犯的错误是把 “技术难度” 当作 moat。“我们做了一件很难的事” 不等于 “别人做不了这件事”。技术难度在 AI 时代衰减得极快——去年的 “难” 今年可能是 open-source library 的一个 function call。
真正的 moat 不是 “你做了什么”,而是 “你做的事情产生了什么飞轮效应”。
变现的时机与定价权
Moat 说的是壁垒,但壁垒不会自动变成收入。创业者需要回答的下一个问题是:什么时候开始收钱,怎么收?
大多数技术创始人的直觉是”先做大用户基数,再考虑变现”。这在移动互联网时代也许可行(用户量足够大时总能找到商业模式),但在 AI 创业中,这个策略有一个致命问题:AI 产品的边际成本不是零。 每一次 API 调用都在烧钱。没有收入的增长越快,死得越快。
一个反直觉的数据点:用户注册时付费,转化率高于在使用过程中卡点付费。
逻辑很简单:用户刚注册的时候,他的耐心和付费意愿处于峰值——他刚做了一个主动选择来到你的产品,这个决策动量还没消退。如果你在这个时刻呈现一个合理的定价方案,他大概率会接受。但如果你让他免费用一段时间,等他习惯了免费,再在某个功能卡点弹出 paywall——你面对的不是一个 “愿意尝试的新用户”,而是一个 “刚被打断工作流的愤怒用户”。
创业需要更早商业化,把付费作为产品体验的一部分来设计,而不是事后追加。 付费墙不是产品的疤痕,它是产品的一部分——就像餐厅的菜单上有价格一样自然。
定价权是另一个被低估的话题。当你做了一个受欢迎的工具,平台随时可以通过调整分成比例、改变算法、或者自己做竞品来夺走你的利润。
定价权的本质是不可替代性。 如果平台能用算法替代你的产品,你就没有定价权。如果用户离开你需要付出巨大的迁移成本,你就有定价权。获取定价权有三条路径:控制供应链(你是唯一的供给方)、控制需求侧(用户习惯和工作流锁定)、或做非标品(无法被标准化替代的定制服务)。在 AI 领域,第三条路最可行——深度垂直的行业 know-how 天然就是非标的。
从工具到网络:SaaS 的终局
在 moat 的五个维度中,网络效应(network effect)是最强大的——也是最容易被误用的概念。不是所有”多人使用”都是网络效应。Slack 有网络效应(同事都在用,你就必须用),但大多数 SaaS 工具没有。
真正的网络效应需要跨越企业边界。Carta 的路径说明了这一点:从单企业 cap table 工具起步 → 足够多创业公司使用后投资人也开始查看投资组合 → 顺势切入 Fund Administration → 单企业 SaaS 变成了跨企业的金融网络。
关键 insight:网络效应不是设计出来的,是从单点工具的渗透中自然涌现的。 先解决一个具体问题,做到足够渗透率,然后发现用户之间存在天然连接需求,顺势搭建连接层。
对创业者的启示:“从 Excel 分化”(做 specific vertical)比”替代 Excel”(做 general platform)是更聪明的路线。 林迪效应告诉你——存在了 40 年的东西预计还会再存在 40 年,正面挑战它几乎不可能赢。
本章小结
这一章从个人技能拉到市场视角,核心论点有五个:
1. AI 产业利润呈微笑曲线。 上游基础设施和下游垂直应用两头高,中游通用模型被挤压。如果你没有 NVIDIA 的资本壁垒,也没有垂直场景的深度 know-how,不要卡在中间。
2. 模型越强,防御性越弱。 能力上升、成本暴跌、知识溢出三重作用下,模型本身不是壁垒。壁垒在网络效应、定价权和垂直数据飞轮。
3. 叙事比技术更重要——但前提是叙事和技术自洽。 从 “Multi-Agent Orchestration Platform” 到 “Cognitive Resilience Engine”,核心技术没变,变的是叙事框架。但叙事不是包装术,它必须和你的架构哲学、商业模式严格自洽。在位者的利润率盲区为创业者提供了窗口期,但你需要用市场语言而非技术语言来抓住它。
4. 技术 moat 的本质是飞轮,不是壁垒。 Proprietary data loop、systems complexity、switching cost、distribution advantage、speed of iteration——这五个 moat 的共同特征是:它们随着时间的推移而增强,而不是被时间侵蚀。Figma 的浏览器优先 PLG 策略是 distribution advantage 的经典案例,HeyGen 的 5 倍速实验复利是 speed of iteration 的极致演绎。
5. 从工具到网络,从收费到定价权。 更早商业化、把付费设计为产品体验的一部分。从单企业 SaaS 到跨企业网络效应(Carta 路径),从 Excel 分化到场景深耕——SaaS 的终局不是更好的工具,是不可替代的节点。
对技术创始人来说,最难的认知转变不是学会新技术,而是学会 用市场的语言描述技术的价值。Technology in search of a market 是一个非常舒适的状态——你可以一直在技术的世界里做你喜欢的事。但创业不允许这种舒适。
下一章我们进入血泪工程:227 张记忆卡片里沉淀的实战教训——那些表面症状和根因之间隔着好几层的坑。