
四月十三号下午四点,dream-works 展示站第一版部署完毕。我打开页面看了一眼:
「这个设计太松散了。不紧致。」
上集说过的设计问题依然没解决——颜色、间距、字体仍然是一团糟。
然后我做了一个不寻常的决定:不自己一条条修,而是启动 OPC 的 tick-based loop,设好定时任务(cron)每 30 分钟触发一次,跟 AI 说「按照这些标准持续改进」。
然后去睡觉了。
什么是 Tick-based Loop
想象一个洗碗机。你把脏碗放进去,设好程序,按下开始。你不需要盯着它——它会自己洗、冲、烘,完成后停下来。
Tick-based loop 就是 AI 的洗碗机模式。每个「tick」是一个独立的工作周期:
- 读取状态文件——了解上一轮做到了哪里
- 决定下一步做什么
- 执行一个小步骤
- 更新状态文件
- 退出,等待下一次 cron 触发
每个 tick 都是独立的 session,不受 context window 的限制。即使某个 tick 失败了,下一个 tick 可以从状态文件恢复。这解决了 AI 最大的硬限制——context 用完了就得重新开始。
通宵运行的真相
从下午四点起,定时任务每 30 分钟触发一次。到晚上十点半我回来检查时,AI 已经无人监管地跑了 6 个半小时——算上后续的人工介入和继续运行,整个 loop 前后持续近 8 小时。
听起来很美对吧?但数据告诉的是另一个故事。
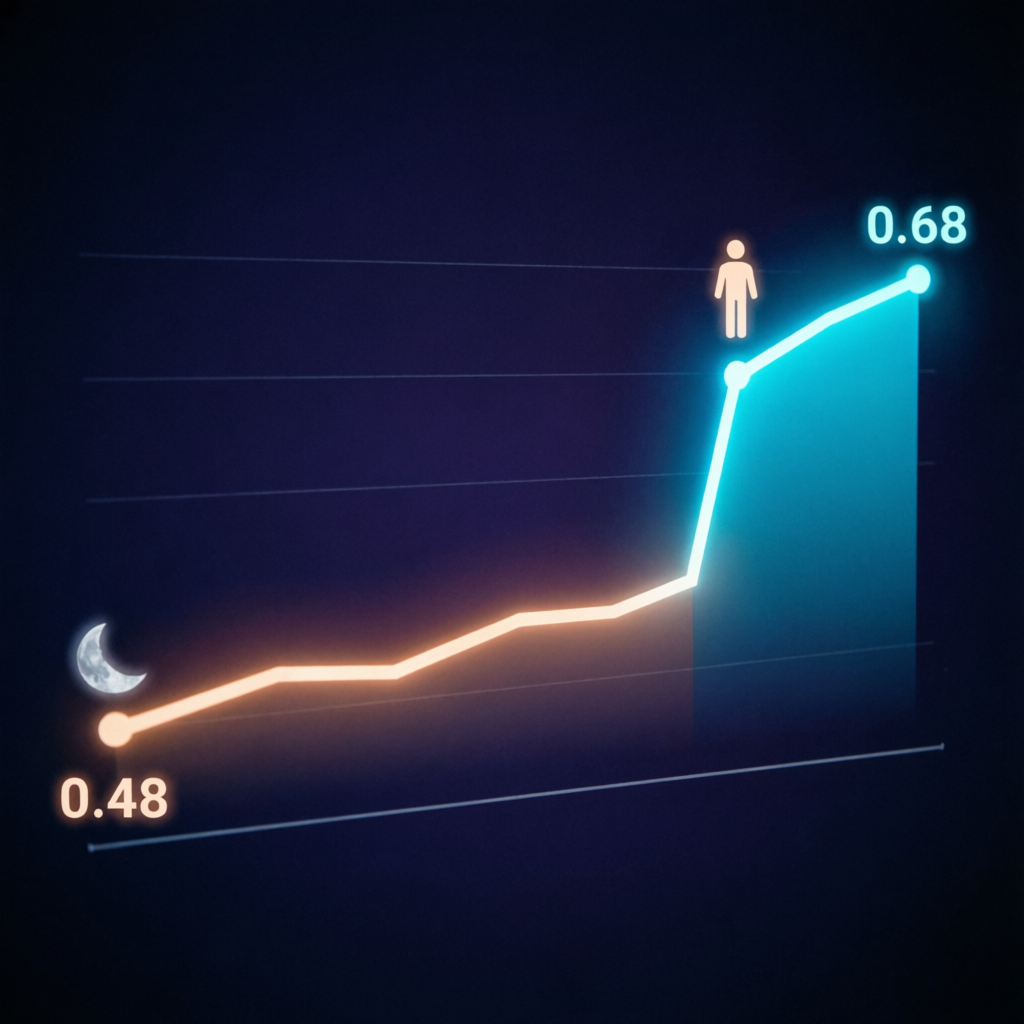
从第 5 个 tick 到第 9 个 tick,质量分数全部是 0.487。Preview 内容完全一致——AI 在反复做同样的事情。它要么在某个点卡住了,要么在不断重复已经完成的工作。
没有人类在场校正方向时,AI 会在错误的方向上 spin。 每个 tick 独立运行,但如果状态文件里的目标定义不够精确,AI 会反复做类似的事情而不知道自己已经做过了。
晚上十点半,我回来了。看了看 AI 的产出,发现了几个问题:它自作主张创建了一个 .harness-dw 目录(没人授权这个命名规范);CSS 改了十几轮但始终在「宽松」和「紧凑」之间来回摆动。
然后我给了一句反馈:「landing page 太松散,图片大小要统一,上面图片下面文字,fit the frame。」
分数从 0.487 跳到了 0.68。
一句话。6 个半小时 vs 一句话。
14 小时建 Logex
但这不意味着 loop 没用。第二天的实验证明了这一点。
四月十四日,我启动了另一个 loop——这次目标更明确:建一个叫 Logex 的产品。验收标准写得很具体:文章列表、Markdown 渲染、左侧导航、分享功能、端到端测试全部通过。
然后又去睡觉了。
这次的结果好得多。整个过夜阶段(8 小时),质量分数稳定在 0.58 左右。不是很高,但很稳。AI 没有在某个点上卡住,而是持续地、增量地把功能一个个实现。
第二天早上起来,UI 已经基本成型了。再花了 6 小时做修正和收尾。总计 14 小时,Logex 从零到可用。
两次实验的区别
为什么第一次 loop 卡在 0.487,第二次稳在 0.58?
差别在于任务的性质。
第一次的任务是「改进设计」——这是一个开放的、需要审美判断的目标。什么叫「不松散」?什么叫「紧致」?AI 没有这个参照系。它能按规则改间距,但不知道改完是不是好看。每个 tick 都在做调整,但没有一个客观标准告诉它「够了」。
第二次的任务是「实现功能列表」——这是一个封闭的、可检验的目标。文章列表要么能显示要么不能。Markdown 渲染要么对要么不对。每个 tick 完成一个具体功能,状态文件记录「还剩哪些没做」,下一个 tick 接着做。
AI 擅长增量打磨,不擅长创造性跳跃。
增量打磨是什么?把一个功能从「不能用」变成「能用」。把一个已知的 bug 修好。把一个明确的需求实现出来。这些都有客观的完成标准,tick-based loop 可以一步步逼近。
创造性跳跃是什么?看了一眼页面说「太松散了」——这个判断包含了审美、经验、对用户心理的理解,AI 没有这个能力。它能执行「把间距从 24px 改成 16px」,但不能自己发现「这里应该更紧凑」。
这就是为什么分数在 0.487 卡了整整 6 个半小时,却在人类回来说了一句话之后跳到了 0.68。那句话的信息密度比 AI 6 个半小时的所有 commit 加在一起都高。
质量天花板
后来在另一个项目(Project P)里,我们又验证了同一个结论。
Baseline 67%。经过 12 个 tick 的 loop 优化,分数达到 71.9%——涨了 4.9 个百分点。听起来不错?但分析显示,这已经是理论最大值的 94%。继续调 prompt 的 ROI 趋近于零。
真正的突破需要什么?不是更多的 tick,而是结构性的变化——换更好的 rubric、升级底层 template、重新设计 delegation 逻辑。这些都不是 loop 内部能做到的——它们需要跳出 loop 的视角。
这让我想到一个比喻:loop 就像一条河。河水会自动往低处流,找到局部最优的路径。但河水不会自己挖一条新河道——那需要挖掘机,需要一个站在地图前面看全局的人。
增量打磨 vs 创造性跳跃
跑了几十次 loop 之后,一条规律浮出水面。
Loop 能高效处理的任务有一个共同特征:你能写出「做完了」的精确定义。 实现一个功能列表、修一组已知 bug、按规范调整样式——这些都是增量打磨。每个 tick 离目标更近一步。
Loop 处理不了的任务也有一个共同特征:需要人类判断「够了」。 设计语言、架构方向、产品定位——这些是创造性跳跃。上面的实验已经证明:AI 在 0.487 卡了 6 个半小时,一句人类反馈就跳到 0.68。
最大的收益不是「AI 更快」,而是「AI 利用了人类的下线时间」。 从每天 8 小时有效工作,变成了 22 小时——剩下的 14 小时,AI 在替你做增量打磨。
就像洗碗机。它不会比你洗得更好。但你在睡觉的时候,碗已经洗好了。
硅基团队 S1: AI 能写代码,凭什么信它? ← S1E04: 让框架长出骨骼 | S1E06: $92 买了一个产品 →