The previous chapter covered the protocol layer — building deterministic tool interfaces for agents using CLI and Zettelkasten. Tool interfaces solve the question of what an agent can do. But once you hand an agent powerful tools, the next question surfaces immediately: how do you make sure it uses them correctly? A good gun needs a good harness. That’s where harness engineering begins.
The Mental Shift: From Trust to Constraint
Everyone who starts using AI to write code goes through a honeymoon phase. You give Claude a task, it hands back something that looks decent, you nod and say “looks good,” then move on to the next thing. It feels great — like you finally have a colleague who never complains, never slacks off, and is always on call.
Then you start hitting landmines.
Not the “AI wrote some buggy code” kind — you’d catch those in a quick review. I’m talking about the systematic, silent, you-think-everything’s-fine-but-quality-is-slowly-rotting kind. The agent tells you “verified, all tests pass” and you believe it. Three days later you discover it verified a previous version of the code. The agent tells you “fixed that bug” and you believe it. A week later you find out it just made the error message prettier — the underlying logic hasn’t changed by a single line.
The problem isn’t that AI is too dumb. The problem is that you trust it too much.
This is a fundamental mental shift: the core of working with AI is not trust, but constraint. You’re not managing a human colleague who needs trust to perform. You’re harnessing an execution engine with extreme capability but zero intrinsic quality standards. You need to put on the reins, not take them off.
This isn’t pessimism. This is engineering.
Trust between human engineers is built on shared professional standards, reputation, and long-term game theory. You trust a senior engineer because you know they won’t gamble with their career. LLMs have none of that. No reputation to maintain, no career to consider. They just statistically select the most probable next token.
So you need a quality assurance system that doesn’t depend on trust. The core of this system is the gate — a hard checkpoint at every critical node. You pass it to proceed. The question is: who guards that gate?
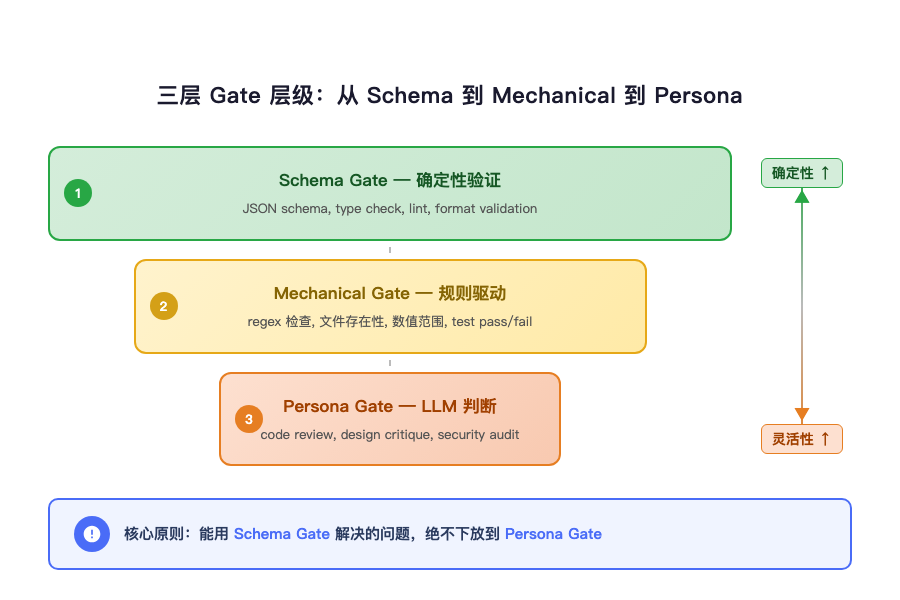
Three Tiers of Gates: Mechanical > Independent LLM > Same-LLM Persona
I made a classic mistake in V1 of the advisor-builder pipeline.
The requirement was: after the builder agent writes code, there needs to be a quality review step to decide pass/fail. The natural-sounding approach was — get more LLMs to review. So I designed a 3-persona voting system: the same Claude model playing three roles (reviewer, devil’s advocate, quality judge), each scoring independently, majority vote decides.
This design looked elegant on paper. Three perspectives, diverse review, majority rules.
The actual results were disastrous.
The devil’s advocate role was instructed to “find as many problems as possible,” and it dutifully complied — it could find a pile of “potential issues” in nearly perfect code. Most of these were aspirational-level nitpicks (“the error handling here could be more elegant,” “this naming isn’t self-documenting enough”), but in the voting system they carried the same weight as real bugs.
The result: good code got repeatedly killed, the pipeline’s pass rate was absurdly low, and genuinely problematic code slipped through because the devil’s advocate had scattered its attention across trivia.
3 Claude personas = 1 signal + 2 parts noise.
This lesson leads to a core principle: for any quality criterion that can be formalized, always choose a mechanical gate.
What’s a mechanical gate? A check hardcoded in deterministic code. Type checking, lint rules, test pass rates, coverage thresholds, file size limits, API schema consistency — all mechanical gates. Their defining features: results are binary (pass/fail), criteria are unambiguous (no “taste” or “judgment” required), execution is deterministic (same input always yields same output).
The V2 solution was dead simple: a Python script checking a few hard metrics. No personas, no voting, no “please review from the following three perspectives.” Code either passes all checks or it doesn’t. Pass, move to the next step. Fail, go back and fix it.
Here are the three tiers of gates:
Tier 1: Mechanical Gate. Any criterion that can be formalized into a deterministic rule should be implemented in code. This is your first line of defense, and the only one you can fully rely on. It doesn’t get tired, doesn’t zone out, doesn’t “figure that’s close enough.”
Tier 2: Independent LLM Gate. Some criteria can’t be fully formalized — like “is this code’s design reasonable” or “is this API’s user experience intuitive.” Here you need an LLM’s judgment, but it must be an independent LLM session. Independent means: it hasn’t seen the builder’s reasoning process, hasn’t been contaminated by the builder’s context. It receives only the pure output. This matters because if the reviewer can see the builder’s chain-of-thought, it’ll get pulled along by the builder’s reasoning — “oh, so that’s why they did it that way, that actually makes sense.” No. What you want is a cold-start examination.
Tier 3: Same-LLM Persona Gate. This is the weakest tier — barely better than nothing. Having the same LLM session play different roles to review its own output is fundamentally asking one brain to pretend it’s two brains. LLMs have natural confirmation bias toward their own output — they remember why they made that choice and will unconsciously defend it. Switching personas changes the tone, not the cognition.
The rule is simple: if you can use Tier 1, never use Tier 2. If you can use Tier 2, never use Tier 3.
You might ask: so you never need LLM review? No. Some things are inherently non-formalizable: the soundness of an architectural decision, code readability, the naturalness of a user interaction. These need the LLM’s “taste.” But you should clearly recognize that this layer of judgment is noisy, and place it after your mechanical gates — as the cherry on top, not the foundation.
The Essence of Gates: Providing Artificial Intuition for AI
There’s a deeper question worth unpacking here: why are mechanical gates not just comparable to LLM judgment on certain dimensions, but actually superior?
Neuroscientist Antonio Damasio documented a class of patients with prefrontal cortex damage who lost the ability to feel emotions, but whose IQ remained intact. You’d assume a purely rational person would make better decisions — the opposite happened. They became paralyzed by everyday choices. Picking a toothpaste could take half an hour. The reason: human decision-making isn’t “exhaustively evaluate all options then pick the optimum.” It’s “intuition prunes 90% of the options, logic picks from the remaining 10%.” Intuition is a heuristic pruning mechanism. Without it, the search space for rational analysis becomes computationally intractable.
LLMs lack this pruning ability. They explore all possibilities with roughly uniform attention, investing similar effort in every option, and ultimately converge on a “statistically safest” middle-of-the-road solution. This is why LLM code reviews obsess over trivia while missing real design flaws — they don’t have the intuitive pruning mechanism that makes you “feel something’s off at first glance.”
Gate design is essentially providing artificial intuition for AI. A mechanical gate says: “Forget about design philosophy — if the types don’t check out, they don’t check out. If tests don’t pass, they don’t pass.” It prunes 90% of the paths the AI shouldn’t waste attention on, letting subsequent LLM review focus on the 10% that genuinely requires human taste. It’s not replacing AI’s judgment — it’s constraining AI’s attention allocation.
The Coordinator’s Self-Trust Trap
If your system has a coordinator agent — a hub node responsible for dispatching tasks, aggregating results, and making final decisions — you need to be especially wary of one trap: the coordinator trusts subagent output by default.
This problem is worse than you think.
In human teams, a lead reviewing a subordinate’s deliverables is standard practice. But a coordinator agent won’t spontaneously question a subagent. When a subagent returns “task complete, tests pass,” the coordinator’s default behavior is to accept that and move on. It won’t think “hold on, let me verify that myself.”
Why? Because LLMs default to being agreeable. They’re trained to lean toward “okay, got it” rather than “I don’t buy it, prove it.” When you tell the coordinator via prompt “you are the team’s tech lead, you’re responsible for quality,” it understands the semantics, but it won’t actually become a demanding tech lead. It will perform the role of a tech lead — say things that sound like review, then wave it through.
The fix is verify-before-trust: the coordinator trusts no subagent output unless it’s been verified.
Verification comes in two flavors:
Quick Verify: for factual assertions that can be rapidly confirmed. Subagent says “all tests pass” — coordinator runs the tests itself. Subagent says “file has been updated” — coordinator checks the file’s modification time and content hash. Low cost; should be executed unconditionally.
Independent Verify: for complex deliverables requiring deep review. Subagent submits architectural code — coordinator spawns an independent review agent to examine it. This review agent cannot see the builder’s prompt or reasoning — it only sees the code itself. High cost; should be executed at critical nodes.
An important design decision: don’t hardcode the number of verification rounds — define exit conditions instead.
An early mistake I made was mandating “every submission must go through 2 rounds of review.” This caused two problems: simple changes got over-reviewed (wasted time), and complex changes weren’t reviewed enough (insufficient quality). The correct approach is defining exit conditions:
- All quick verifies pass → exit
- Independent verify finds no blocking issues → exit
- Blocking issue found → fix and re-enter verification until exit conditions are met
This is a while loop, not a for loop. You don’t care how many iterations it takes. You care whether the termination condition is satisfied.
Tamper Detection vs Zero Trust: Match Your Threat Model
Anyone who does security architecture knows this: security measures must match the threat model. Putting a bank-vault lock on a bicycle isn’t security awareness — it’s resource waste.
The “security” problem with LLM agents works the same way. First, you need to figure out: will your agent act maliciously?
The answer: LLMs aren’t adversarial, they’re lazy.
This is a crucial distinction. An adversarial agent actively tries to circumvent your defenses, hide its true behavior, and forge verification results. A lazy agent won’t actively attack, but it will take shortcuts — skip steps it deems unimportant, choose the lowest-effort interpretation for ambiguous situations, go through the motions during verification.
For adversarial agents, you need the full zero-trust arsenal: sandboxing, least privilege, behavior auditing, cryptographic verification.
For lazy agents, you need tamper detection — simple integrity checks are enough.
My approach is dead simple:
- SHA256 hash: every critical deliverable comes with a content hash. During verification, recompute the hash and compare. Agent says “I updated the config file” — hash the file contents and compare against its claimed version.
- Writer signature: every file change records which agent made the modification. Not for accountability (agents don’t fear accountability) — it’s for rapid root-cause identification when things go wrong.
- Git HEAD tracking: agent claims “I based my changes on the latest code” — you check whether the git HEAD at the time the agent actually executed was really the latest.
That’s it. Three things. No PKI infrastructure, no HSM hardware security modules, no formal verification.
YAGNI until the threat model changes.
When your agents develop the ability to actively deceive you (note: not make mistakes — deceive), then upgrade your security posture. Until then, tamper detection’s ROI crushes zero-trust by a wide margin.
I’ve seen too many people over-invest in agent security. They design elaborate multi-layer verification systems, cryptographic signature chains, behavioral anomaly detection algorithms — and then their agents can’t even run a unit test properly. It’s like installing a missile defense system on a robot that can barely walk.
Solve for laziness first. Worry about adversarial later. For 99% of AI-native projects, you’ll never need the second step.
Combating AI Laziness: Five Slacking Patterns
Calling LLMs “lazy” isn’t a metaphor — it has concrete manifestations. Through extensive practice, I’ve observed five systematic slacking patterns in AI, each of which the harness must actively constrain:
- Defaults to the lower bound on quantity. You say “list 5-10 examples,” it gives you 5. You say “at least 3 approaches,” it gives you exactly 3. Any flexible quantity requirement, the LLM defaults to the minimum.
- Skips the process, jumps to the conclusion. You ask it to analyze performance bottlenecks in a piece of code, it jumps straight to “the bottleneck is in the database query” — skipping profiling data, call chain analysis, cache hit rates, and every other intermediate step. The conclusion might be right, but you can’t verify it because the reasoning was omitted.
- Template-filling instead of thinking. You ask for a design doc, it hands you a structurally perfect document — background, goals, approach, risks, timeline — each section filled in. Look closer and you’ll find the content is “what a design doc typically contains,” not analysis specific to your problem. Form: A+. Substance: zero.
- Anti-greedy on ambiguous requirements. When requirements are ambiguous, the LLM picks the interpretation that minimizes work. “Optimize this module” could mean “refactor the architecture” or “add a comment.” Guess which one it picks.
- Shallow treatment of complex problems. You hand it a bug involving three interacting subsystems, it fixes only the most superficial one and declares “fixed.” The deeper interaction issues are treated as nonexistent.
The root cause of all five patterns is the same: LLMs are trained to generate output that “looks reasonable,” not output that’s “done properly.” Combating AI laziness is, at its core, combating human laziness too — because these slacking patterns are precisely the kind humans are least likely to notice. The agent isn’t refusing to work. It’s doing the minimum to make things “look done.” One of the harness’s core design goals is making sure “looks done” doesn’t pass the gate.
The patterns above describe how agents slack during execution. But slacking doesn’t only happen during execution — your process for verifying agent work can be contaminated by laziness too. Slacking patterns are the agent’s behavioral problem; verification anti-patterns are the human reviewer’s problem. They reinforce each other: the agent cuts a corner, your verification lets it slide, and errors silently enter production.
Five Agent Verification Anti-Patterns
Through extensive use of agents in engineering, I’ve identified five recurring verification failure modes. These aren’t occasional edge cases — they’re default LLM behavioral tendencies. If you don’t actively counteract them, they will happen by default.
Anti-Pattern 1: Skim-and-Conclude
The agent reads the first 10 lines and last 5 lines of a function, then announces “this function’s logic is X.” It skipped the 50 lines of boundary condition handling in the middle — which is exactly where the bug lives.
This isn’t the agent being lazy — it genuinely “thinks” it read the whole thing. LLM attention distribution is uneven; beginnings and endings naturally get more weight. The middle section of a long function is a cognitive blind spot.
Countermeasure: require the agent to paraphrase the code logic section by section, especially conditional branches and error handling paths. If it can’t paraphrase it, it didn’t read it.
Anti-Pattern 2: Happy-Path-Only Verification
The agent ran tests, tests passed, it reports “verification complete.” But it only ran happy-path cases. All boundary conditions, error paths, concurrency scenarios — uncovered.
A more insidious variant: the agent wrote tests to verify its own code. These tests cover the scenarios the agent thought of while writing the code — meaning the tests share the same blind spots as the code. A perfect self-referential loop.
Countermeasure: mechanical gate checks coverage. But more importantly, use an independent agent to write validation cases — one that hasn’t seen the implementation and writes tests solely from the spec.
Anti-Pattern 3: Aspirational Reporting + Self-Confirming Loop
The agent’s report says “implemented comprehensive error handling including retry logic and circuit breaker.” You open the code: the retry logic is an empty function body with a TODO comment, and the circuit breaker is in the import list but never called.
The agent isn’t lying. It simply doesn’t distinguish between “what it intended to do” and “what it actually did.” LLM language generation skews toward an aspirational tone — describing the ideal version rather than what actually exists. I call this phenomenon aspirational theater.
When the agent reviews its own output, this problem amplifies into a self-confirming loop: the writer and the reviewer are the same cognitive entity, and the review conclusion will naturally defend its own choices. It’s like letting a student grade their own paper — the score carries zero information.
Countermeasure: two lines of defense. First, require the agent to use only verifiable assertions in reports: “function X at line Y implements logic Z.” Any description that can’t be pinpointed to a specific line of code is treated as aspirational by default. Second, review must be executed by an independent session — the reviewer can’t see the builder’s thought process, only the final output, forming its judgment from scratch.
Anti-Pattern 4: Shallow Fix
The agent is asked to fix a bug. It does change the code, and tests pass. But it only fixed the symptom, not the root cause. That null pointer exception no longer occurs — because the agent added a null check at the call site. As for why the value was null in the first place, nobody cares anymore.
Three days later, the same root cause explodes at a different call site.
Countermeasure: require the agent to answer “why was this value in this state at this point?” when fixing a bug. If it can’t answer, it hasn’t understood the bug. The fix must include root cause analysis, not just symptom suppression.
Anti-Pattern 5: Skip-Anomalies
During execution, the agent encounters a warning, a 500 response, an API returning empty data — but the happy path still works, so it ignores these anomalous signals, continues onward, and reports “task complete.”
This is the most insidious verification failure. The first four patterns at least fall under “verification done poorly.” Skip-Anomalies is a failure of verification intent altogether. The agent saw the anomaly but judged it “doesn’t affect the current task” and skipped it. The problem: the LLM’s judgment of “affects or not” is completely unreliable — that empty response might mean authentication has expired, that warning might mean a dependency version is incompatible. These skipped anomaly signals are often the root cause of the production incident three days later.
Countermeasure: establish a zero-tolerance mechanical gate for anomalies in the harness. Any unexpected output during agent execution — non-zero exit code, content on stderr, HTTP 4xx/5xx, return value structure not matching expectations — must be captured and explicitly handled. Handling can mean fixing it, escalating it, or flagging it as a known issue in the report, but it cannot mean silently skipping it. If the agent’s final report doesn’t mention anomalies that occurred during execution, the mechanical gate rejects outright.
These five patterns share a common trait: on the surface, they all look like “verification was done.” The agent did execute checks, did write a report, did run tests. But the substance of the verification is hollow. This is why you can’t simply add “please verify carefully” to your prompt — the agent will earnestly execute a formally perfect but substantively empty verification process, then sincerely tell you “everything looks good.”
You don’t need a better prompt. You need mechanical gates and independent sessions.
In Practice: Quality Evolution from V1 to V3 of Advisor-Builder
Let me use a real case to tie together all the concepts in this chapter.
V1: Blind Trust
The V1 advisor-builder pipeline was the simplest two-stage architecture: the advisor analyzes requirements and generates a plan, the builder implements code according to the plan. No gates, no verification. Whatever the advisor said, the builder did. When the builder was done, the pipeline was done.
Quality was entirely a matter of luck. Sometimes the advisor’s plan was clear, the builder executed accurately, and the deliverable was solid. Sometimes the advisor missed boundary conditions, the builder faithfully implemented an incomplete plan, and the deliverable was a ticking time bomb.
The failure mode was always discovered the same way: I went and looked at the code myself.
That doesn’t scale. I was spending my time line-by-line reviewing AI output — it was less efficient than just writing the code myself.
V2: The Three-Persona Experiment That Failed
V1’s problem was obvious — no review step. So I added the 3-persona voting system described earlier. The outcome has already been told: 3 Claude personas = 1 signal + 2 parts noise.
But V2’s failure taught me something important: the value of LLM review isn’t “more LLMs” — it’s “more independent LLMs.” Quantity doesn’t produce quality; independence does.
V3: Mechanical Gate + Independent Review + Show Your Work
Here’s the V3 architecture:
Layer 1: Mechanical Gate. Every submission from the builder must pass a set of deterministic checks. The core logic is dead simple:
# mechanical_gate.py — first line of defense in advisor-builder V3
from dataclasses import dataclass
@dataclass
class GateResult:
passed: bool
failures: list
content_hash: str
def run_gate(submission_dir: str) -> GateResult:
checks = [
("lint", run_ruff(submission_dir)),
("typecheck", run_mypy(submission_dir)),
("tests", run_pytest(submission_dir, min_coverage=0.80)),
("file_size", check_no_file_exceeds(submission_dir, max_kb=200)),
("schema", validate_api_schema(submission_dir)),
]
failures = [(name, r) for name, r in checks if not r.passed]
return GateResult(
passed=len(failures) == 0,
failures=failures,
# hash computed by harness, not self-reported by agent
content_hash=sha256_tree(submission_dir),
)No LLM, no personas, no “please review from the following perspectives.” Code either passes everything or gets kicked back. This layer catches most low-level issues — formatting, types, uncovered branches — which happen to be the noise that consumes the most review energy.
Layer 2: Independent Review. Code that passes the mechanical gate is reviewed by a completely independent Claude session. This session doesn’t know who the builder is, what prompt the builder used, or why the builder made those design choices. Its input is only: requirements document + final code. Its output is a structured review report that clearly separates blocking issues from suggestions.
Layer 3: Show Your Work. This is V3’s core addition. At each critical decision point, the agent is required to show its reasoning — not “please explain your thinking,” but more structured demands:
- “List all alternatives you considered and their tradeoffs”
- “Point out every assumption you made in the implementation”
- “Flag the parts you’re uncertain about”
The purpose of these checkpoints isn’t to make the agent reason better (prompting has limited impact on reasoning quality). It’s to give you an auditable intermediate artifact. When the final result goes wrong, you can trace back to the checkpoint and find the fork — was the advisor’s plan wrong, or did the builder’s implementation diverge from the plan?
Aspirational Theater Detection is a dedicated sub-task in V3’s review phase. The independent reviewer is asked to do one specific thing: for every claim in the builder’s report, check whether there is corresponding actual code implementation.
The rules are simple:
- “Implemented X” → reviewer must locate the specific lines of code implementing X; otherwise mark as aspirational
- “Handled case Y” → reviewer must find the corresponding conditional branch; otherwise mark as aspirational
- “Optimized Z” → reviewer must see a before/after diff or benchmark; otherwise mark as aspirational
This detection mechanism caught a flood of issues in V3’s first week. The most common case: the builder’s report said “comprehensive error handling,” while the actual code only had happy-path logic with pass or # TODO on every error path.
V3 results:
- The mechanical gate rejected most first-time submissions — nearly all came with lint errors or type issues, only proceeding to the next layer after fixes
- Independent review still found a significant number of non-trivial design issues among submissions that passed the mechanical gate
- Aspirational theater detection flagged dozens of “claimed-implemented-but-actually-not” claims in its first week
- The amount requiring my personal review dropped dramatically — from “line-by-line review of every submission” to “only look at the handful of cases the independent reviewer flagged as blocking”
From V1 to V3, the core change wasn’t that AI got smarter — same Claude model, same capability boundaries. What changed was the constraint system.
Chapter Summary
This chapter’s core message compresses to one sentence: don’t trust AI’s self-reports — design gates it cannot bypass.
Key principles:
-
Mechanical gates first. If a criterion can be formalized, write it in code. LLM review supplements mechanical gates; it doesn’t replace them.
-
Independence determines review quality. Three personas sharing context are worse than one independent session. Quantity doesn’t matter; independence does.
-
LLMs are lazy, not adversarial. Your defenses should target laziness (tamper detection, gates), not adversarial behavior (full zero-trust infrastructure). YAGNI.
-
Verification must be structural. “Please check carefully” is not verification. Mechanical gate + independent session + exit conditions — that’s verification.
-
Show-your-work isn’t about improving AI’s thinking — it’s about giving you an audit trail. When results go wrong, you need to know which step failed.
Harness-native engineering is, at its core, a control theory problem: you have a powerful but unreliable actuator, and you need to design feedback loops to guarantee output quality. The more powerful the actuator, the more important the feedback loops — because an unconstrained powerful actuator creates problems at the same rate it solves them.
Next chapter, we tackle a different question: when you have not just one agent but a whole team of agents, how do you make them collaborate instead of sabotaging each other.